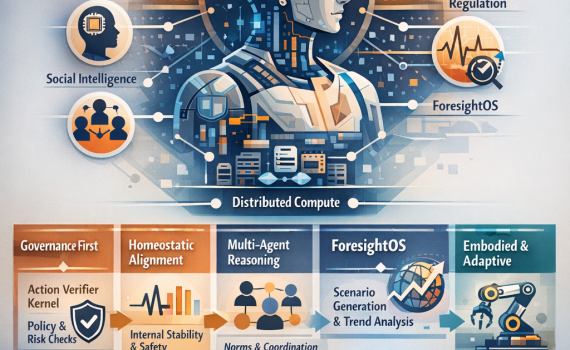
Most AI agents still behave like clever chat systems with tools. This article lays out a governed organism style architecture that treats regulation, memory, identity, social reasoning, and foresight as first class system layers. You get a deployable stack for digital twins and high stakes environments, with verifiable action selection and long horizon coherence.
homeostatic reinforcement learning
1 post