
The Unseen Digital Epidemic
In the gleaming offices of Silicon Valley, where the future of AI is being written line by line, a silent crisis is unfolding. While tech executives tout ever more powerful language models, a fundamental problem lurks beneath the surface: the very success of AI is poisoning the well from which future AI systems will drink.
This isn’t science fiction it’s happening right now. Every day, AI systems generate approximately 100 billion words of text, flooding the internet with synthetic content that will inevitably become training data for tomorrow’s models. We’re witnessing the birth of a feedback loop that threatens to fundamentally alter the trajectory of artificial intelligence development.
The implications are staggering. By 2026, researchers predict we may exhaust the supply of high quality human generated text suitable for AI training. What comes next could determine whether AI continues its meteoric rise or enters a period of decline that some are already calling the “AI winter.”
Not having all the prerequisite technical insights I have written an explainer and outline: Challenges of LLMs using data and articles created by other LLMs hoping readers will develop and take forward. If you were designing and creating a new large language model (LLM), what features or improvements would be considered for the Synthetic Content Era: Design Considerations for the Synthetic Content ERA
The Seven Horsemen of AI’s Apocalypse
1. Model Collapse: The Digital Decay
Imagine photocopying a photocopy, then copying that copy, and so on. Each generation becomes slightly more degraded, with artifacts and distortions compounding until the final result bears little resemblance to the original. This is exactly what’s happening to AI models trained on synthetic data.
Research published in Nature has demonstrated this phenomenon, dubbed “model collapse,” in simplified systems. When language models are trained on content generated by other AI systems, they begin to “forget” the rich diversity of human expression. The subtle nuances, edge cases, and creative flourishes that make human language vibrant start to disappear, replaced by the statistical averages that AI systems naturally gravitate toward.
The timeline is more compressed than many realize. Early signs of measurable degradation in commercial models are expected by 2025-2026, with widespread recognition of the problem following by 2027-2028. By 2029-2030, we may see significant performance reversals in new model releases—a sobering prospect for an industry built on the assumption of continuous improvement.
2. The Contamination Cascade
The internet, once a pristine source of human knowledge and creativity, is rapidly becoming contaminated with AI-generated content. Current estimates suggest that 20-30% of new internet text is already AI-generated, with projections indicating this could reach 50-70% by 2026-2027.
This contamination isn’t uniformly distributed. High quality sources academic papers, professional journalism, carefully curated databases remain relatively clean. But the vast majority of web content, the kind that fills training datasets through automated scraping, is increasingly synthetic.
The challenge is detection. AI-generated content has become sophisticated enough that it’s often indistinguishable from human writing without specialized tools. This creates a data laundering effect, where synthetic content masquerades as authentic human expression, gradually shifting the baseline of what AI systems learn to emulate.
3. Amplification of Errors and Biases
Perhaps more concerning than the gradual degradation of quality is the amplification of systematic errors and biases. When an AI system generates biased or factually incorrect content, and that content is then used to train subsequent models, these flaws become embedded and magnified across generations.
This creates a dangerous feedback loop. Small biases in early models become pronounced biases in later ones. Occasional hallucinations become systematic misinformation. The democratic ideal of AI systems learning from the collective wisdom of humanity gives way to an echo chamber of algorithmic assumptions.
The implications extend beyond technical performance. AI systems are increasingly used for critical decisions in healthcare, finance, education, and criminal justice. Degraded models trained on contaminated data could perpetuate and amplify societal biases at unprecedented scale.
4. The Attribution Abyss
In traditional academic and journalistic contexts, attribution is fundamental. We cite sources, acknowledge influences, and build upon the work of others transparently. But in the world of AI training, content is often stripped of context and attribution, creating a vast commons of unmarked information.
This lack of transparency makes it nearly impossible to trace the origins of AI-generated content or understand the provenance of training data. When AI systems produce outputs, we can’t easily determine whether they’re drawing from human knowledge, synthetic content, or some hybrid combination.
The problem is compounded by the scale of modern AI training. Models are trained on billions of documents scraped from across the internet. Manual verification of sources is impossible, and automated detection methods are still evolving. This creates a fundamental accountability gap that undermines both the reliability of AI systems and the ability to address contamination when it’s detected.
5. Circular Knowledge Loops
One of the most insidious aspects of AI content contamination is the creation of circular knowledge loops. When AI systems begin citing other AI-generated content as authoritative sources, they create closed circuits of information that don’t connect back to real-world verification or human knowledge.
These loops can persist and even strengthen over time. An AI system might generate a plausible but incorrect “fact,” which then gets incorporated into training data for future models. Those models, having seen this “fact” multiple times across different sources, might assign it higher confidence, leading to its further propagation.
The result is a gradual drift away from ground truth. Information becomes increasingly self-referential, disconnected from the empirical reality it’s supposed to represent. In extreme cases, this could lead to the creation of entirely fictional “knowledge” that becomes deeply embedded in AI systems’ understanding of the world.
6. Legal and Ethical Minefields
The contamination of training data with AI-generated content raises profound legal and ethical questions. Who owns the copyright to synthetic content? What constitutes fair use when training data includes material generated by other AI systems? How do we ensure proper attribution and compensation for original creators when their work becomes part of a synthetic content ecosystem?
These questions are already being tested in courts around the world. Recent rulings have provided some clarity—judges have sided with companies like Anthropic and Meta that training on publicly available text can constitute fair use under certain circumstances. However, parallel lawsuits continue, and the legal landscape remains unsettled.
The stakes are enormous. The AI industry has invested billions in developing and deploying language models. If legal challenges succeed in restricting access to training data or requiring retroactive licensing agreements, it could fundamentally alter the economics of AI development.
7. The Evaluation Trap
Perhaps most troubling is the breakdown of evaluation systems. As AI-generated content infiltrates not just training data but also the benchmarks used to assess model performance, it becomes increasingly difficult to measure genuine progress.
If both training data and evaluation metrics contain synthetic content, models might appear to perform better while actually becoming less capable of handling real-world tasks. This creates a dangerous illusion of progress that could mask fundamental degradation in model quality.
The contamination of benchmarks is particularly insidious because it’s often invisible. A model that achieves high scores on contaminated benchmarks might fail catastrophically when deployed in real-world scenarios that require genuine understanding and reasoning.
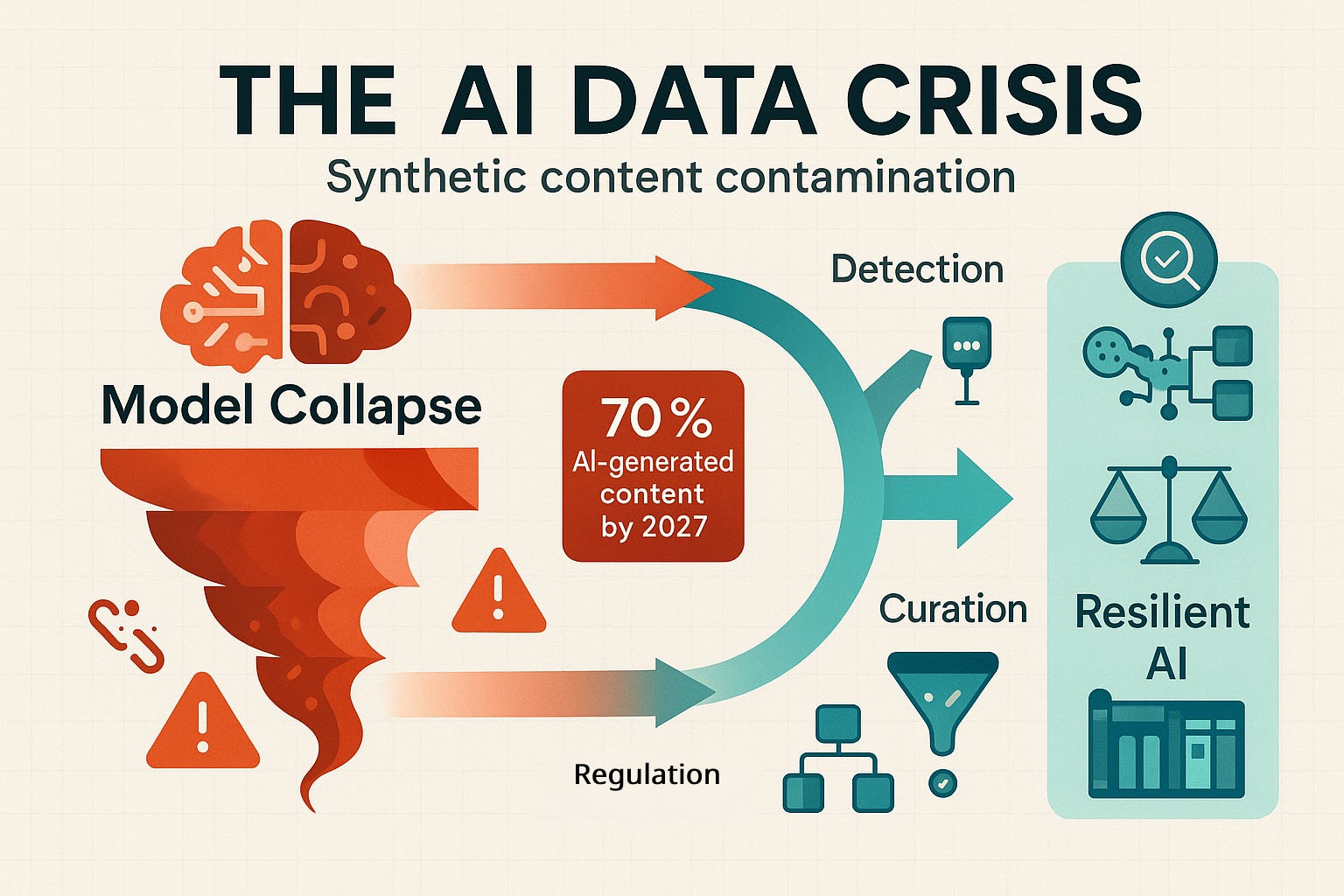
The Industry Awakens: Current Responses and Solutions
Despite the gravity of these challenges, the AI industry is not standing idle. Major laboratories, standards bodies, and regulators are implementing increasingly sophisticated approaches to address contamination and model collapse.
Detection and Prevention Technologies
Leading AI companies are deploying ensemble detection models that combine statistical analysis, neural network classification, and watermarking techniques to identify synthetic content. These systems create confidence scores for AI-generated content likelihood and implement real-time scanning pipelines for training data ingestion.
The technical approaches are becoming increasingly sophisticated. Invisible watermarking technologies, like Google’s SynthID, are being integrated into production systems. Content fingerprinting using perceptual hashing helps identify duplicate and derivative content. Advanced provenance tracking systems create immutable records of content origins and transformations.
Regulatory Frameworks and Standards
The regulatory response is accelerating. The EU AI Act, set to take effect in August 2025, will impose transparency, bias-testing, and energy-reporting obligations on large AI models. The act requires providers to watermark synthetic outputs and disclose training data use, creating the first comprehensive legal framework for AI content authenticity.
Industry standards are also emerging. ISO/IEC 42001, the first management system standard for AI, provides structured approaches to risk control. The Coalition for Content Provenance and Authenticity (C2PA) is developing cryptographically-signed content credentials that make it trivial to filter out known AI material during data collection.
Innovative Technical Solutions
The most promising developments may come from novel technical approaches that go beyond traditional detection methods. Adversarial provenance networks use generative adversarial training to create increasingly sophisticated detection systems. Quantum-inspired fingerprinting techniques promise unforgeable content signatures. Biological evolution-based training methods introduce controlled diversity to prevent monoculture in AI development.
Some companies are implementing “synthetic data vaccination” strategies, where small amounts of known synthetic content are intentionally included in training to build immunity against contamination. Others are developing “temporal causality enforcement” systems that use blockchain-based timestamps to prevent future content from influencing past models.
The Path Forward: Building Resilient AI Systems
The challenges facing AI development are real and urgent, but they are not insurmountable. The key lies in implementing comprehensive approaches that address contamination at multiple levels while maintaining the innovative momentum that has driven recent progress.
Hybrid Data Strategies
The most successful approaches combine human-generated content with carefully managed synthetic data. Leading laboratories now start each training run with a small “anchor” of high quality human data, then layer in synthetic content that has been deduplicated, scored, and periodically refreshed.
This hybrid approach recognizes that synthetic data isn’t inherently problematic it’s the uncontrolled proliferation and inadequate filtering that creates risks. When properly managed, synthetic data can actually enhance training by providing diverse examples and filling gaps in human-generated datasets.
Technological Innovation
The development of robust detection and prevention technologies is accelerating. Machine learning techniques for identifying synthetic content are improving rapidly, with new approaches emerging regularly. Watermarking and fingerprinting technologies are becoming more sophisticated and harder to circumvent.
Perhaps most importantly, the industry is developing new evaluation frameworks that are resistant to contamination. These include “golden datasets” with verified human only content, temporal evaluation splits that separate pre-LLM and post-LLM era content, and contamination-aware benchmarks that account for potential synthetic content in test sets.
Industry Collaboration
The scale of the contamination challenge requires industry wide cooperation. No single company can solve this problem alone. Collaborative efforts to share detection technologies, establish common standards, and create shared datasets of verified human content are essential.
Professional organizations, academic institutions, and industry consortiums are playing crucial roles in coordinating these efforts. The development of open-source tools and frameworks helps democratize access to contamination detection and prevention technologies.
Conclusion: The Crossroads of AI Development
We stand at a critical juncture in the development of artificial intelligence. The next 1-2 years will likely determine whether the AI revolution continues its upward trajectory or encounters significant obstacles that could reshape the entire industry.
The contamination of training data with synthetic content represents one of the most significant challenges facing AI development today. But it’s also an opportunity—a chance to build more robust, transparent, and accountable AI systems that can serve humanity’s long-term interests.
The solutions exist. Detection technologies are improving rapidly. Regulatory frameworks are taking shape. Industry collaboration is increasing. The technical approaches needed to address contamination are being developed and deployed.
Success will require sustained effort across multiple domains: technical innovation, regulatory clarity, industry cooperation, and public awareness. The companies and countries that navigate this challenge most effectively will likely emerge as leaders in the next phase of AI development.
The future of AI isn’t predetermined. The choices we make today about data quality, model training, and evaluation standards will shape the capabilities and limitations of AI systems for decades to come. The stakes couldn’t be higher, but neither could the potential rewards.
As we write the next chapter of the AI revolution, we must ensure that tomorrow’s models are not just more powerful than today’s, but more truthful, more diverse, and more aligned with human values. The digital epidemic of synthetic content contamination is serious, but it’s not terminal. With the right approaches, we can build AI systems that learn from the best of human knowledge while avoiding the pitfalls of recursive synthetic generation.
The question isn’t whether we can solve this challenge—it’s whether we will act quickly and decisively enough to prevent a future where AI systems become echo chambers of their own making. The answer to that question will determine not just the future of AI, but the future of knowledge itself.
This analysis is based on current research and industry developments as of early 2025. The AI landscape is evolving rapidly, and new developments may alter these projections. For the latest updates on AI safety and development, follow our ongoing coverage of the intersection between technology and business strategy. References in outline document Challenges of LLMs using data and articles created by other LLMs




{kind=link}
{kind=link}
{kind=link}
{kind=link}