A Living System for Self-Understanding, Digital Identity, and Intentional Discovery

Preamble
We live inside our data, yet we rarely see ourselves within it.
Every day we watch, like, comment, save, scroll, listen, reply, bookmark, ignore. These actions form an invisible autobiography fragmented across platforms, buried in feeds, optimized for advertisers rather than for us. The Personal Interaction Chronicle exists to reverse that asymmetry.
It is not another productivity tool, nor a quantified-self dashboard. It is a reflective infrastructure a system that gathers the traces of our digital lives and returns them as meaning, narrative, and agency.
This document articulates the vision, system logic, risks, and roadmap for transforming digital exhaust into a coherent, portable, and interpretable portrait of self.
As usual some related artefacts :
A Structured catalogue of application concepts
1. Vision & Concept Narrative
Vision Statement
A world where your digital interactions are not lost to algorithms, but woven into a living chronicle of who you are how you think, what you care about, and how you evolve over time.
Concept Overview
The Personal Interaction Chronicle is an AI-orchestrated platform that:
- Aggregates a user’s cross-platform digital interactions
- Interprets them through narrative, analytical, and visual lenses
- Produces a dynamic “virtual self” a reflective, queryable, and extensible identity layer
This system operates at the intersection of:
- Journaling & introspection
- Behavioral analytics
- Identity design
- Search & discovery
- Ethical AI interpretation
Rather than predicting what you should consume next, it asks:
Who are you becoming and what patterns are shaping you?
Design Philosophy
- User-Owned Meaning: Data is raw material; insight belongs to the individual.
- Narrative Over Metrics: Stories and trajectories matter more than scores.
- Interpretive AI, Not Directive AI: The system reflects—it does not prescribe.
- Modularity: The Chronicle is a layer, not a silo.
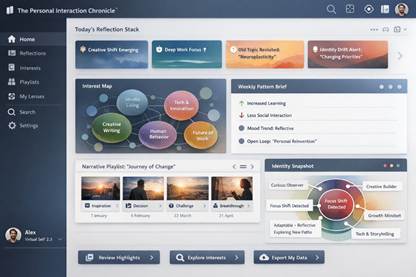
“For You Dashboard”
Here are practical equivalents of a “For You” page, interest feed, playlist, and user-defined categories for your Chronicle. Split into into algorithmic and user-defined versions, because the best experience usually blends both.
1) “For You” page equivalents
Algorithmic equivalents
- Today’s Reflection Stack
A ranked set of 5 to 15 items from your recent data, such as moments, themes, shifts, contradictions, and unfinished threads. Ranking uses recency, novelty, and personal importance signals. - Weekly Pattern Brief
A one page digest of changes, repeating topics, mood and tone shifts, and time allocation patterns. - Open Loops and Returns
Topics you repeatedly revisit over weeks or months. Useful for spotting deep interests rather than trends. - Identity Drift Alerts
Detected shifts in your language, values, or attention. Presented as “possible change” with confidence, not as fact. - Commentary and interactions :View : comments, liked , saved, shared and or similar categories with timeline and
- Deep Dive: Review, sort, categorises, create journal save format , add notes etc
User-defined equivalents
- My Daily Check In
You choose what appears, for example “new themes,” “creative work,” “relationships,” “career,” “faith,” “health,” or “finance.” - Pinned Lenses
You select 3 to 7 lenses you want to view yourself through. The home page becomes those lenses, not a generic feed. - Manual Highlights
You can bookmark moments and annotate why they mattered. The home page prioritizes what you marked as meaningful.
2) Interest “analysis” equivalents
Algorithmic equivalents
- Interest Map
A dynamic graph of topics and subtopics, showing growth, decline, and connections over time. - Interest Timeline
A time series view of top themes by week or month, with spikes explained by source events. - Theme Clusters
AI groups related content into clusters like “creative identity,” “politics and society,” “product building,” “family,” “spiritual reflection,” then shows what content drove each cluster. - Influence Tracing
For a theme, AI lists key inputs that pushed it, such as creators you watched, communities you joined, or articles you read.
User-defined equivalents
- My Interests Library
You define interests and attach rules, keywords, and examples. The system then files items into those buckets. - Interest Strength Sliders
You can say, “this matters more to me now.” The system uses that as a weighting signal for surfacing content. - My Definitions
You can rename topics in your language. Example, “future work” instead of “labor market trends.”
3) Playlist equivalents
Think “playlist” as a curated sequence of moments, artifacts, or reflections you can replay.
Algorithmic equivalents
- Narrative Playlists
“My last 30 days,” “The year my focus changed,” “My build journey,” “When I got stuck and why.” - Mood and Energy Playlists
Sequences built from tone markers in your writing and browsing behavior, with caution and transparency since tone inference can be wrong. - Learning Trails
A stitched sequence: what you searched, what you read, what you saved, what you wrote, and what you concluded.
User-defined equivalents
- Curated Life Threads
You drag and drop items into a storyline and add commentary. - Project Playlists
“MedConnect build,” “PersonaForge,” “Colour Equity OS,” etc. Each playlist becomes a portable project history. - Collections for Sharing
A cleaned, exportable playlist you can share as a portfolio, a case study, or a personal recap.
4) User-defined categories equivalents
Algorithmic equivalents
- Auto Categories
AI creates categories from behavior, then asks you to confirm, rename, merge, or delete them. - Event Based Categories
“Conference month,” “job search phase,” “moving house,” “launch sprint,” created from date ranges and activity shifts. - Relationship to Self Categories
“Aspirational,” “Avoidance,” “Curiosity,” “Doubt,” “Commitment,” based on how you engage, not just what you engage with.
User-defined equivalents
- Folders, Labels, and Rules
Categories that work like Gmail labels. You define rules like keywords, sources, or time windows. - Lenses
Higher level categories that change how everything is interpreted. Example lenses: “career,” “faith,” “family,” “creative practice.” - Identity Facets
Categories that represent parts of you, not topics. Example: “builder me,” “researcher me,” “mentor me.”
How to blend algorithmic and user-defined cleanly
A workable model is a 3-layer system:
- Raw stream: everything comes in, timestamped, source tagged.
- AI suggested filing: AI proposes themes, playlists, and relevance.
- User governance: you approve, rename, and set weights. Your choices teach the system.
Practical ranking signals you can use for the “For You” stack
- Recency, but capped so old important items can return.
- Repetition across time, which signals depth.
- Novelty, when a new cluster appears.
- Self-marked importance, such as bookmarks, notes, and “this matters.”
- Conflict and contradiction detection, only if you want it, because it can feel intrusive.
- Coverage confidence, so low data weeks do not produce fake certainty.
2. Stakeholder Identification
| Stakeholder | Role | Motivations | Unmet Needs | Value Derived |
| Individual Users | Core users | Self-understanding, clarity, continuity | Fragmented identity, lost history | Coherent self-portrait, insight, agency |
| Creators / Knowledge Workers | Power users | Reflection, positioning, synthesis | Scattered output, weak signal | Narrative archive, personal knowledge graph |
| Researchers / Analysts | Secondary users | Pattern discovery | Lack of longitudinal personal data | Consent-based, structured insight |
| Platform Integrators | Ecosystem partners | Value-added services | User churn, shallow engagement | Deeper user meaning layers |
| Regulators & Privacy Bodies | Oversight | Data protection | Opaque aggregation tools | Transparent consent, auditability |
| Future Enterprises (Opt-in) | Commercial adopters | Persona matching, discovery | Poor human context | Ethical identity interfaces |
3. Needs → Features → Functional Requirements
Core Stakeholder Needs
- Understand personal behavior over time
- Reclaim fragmented digital history
- Explore identity, not just activity
- Use the self as a discovery and search lens
- Maintain sovereignty over personal data
Core System Features
| Need | Feature | Functional Requirement |
| Reflection | Automated AI Journaling | Convert interactions into narrative entries |
| Pattern Insight | Behavioral Analysis Engine | Detect themes, moods, rhythms |
| Identity Coherence | Virtual Self / Persona Layer | Unified, evolving identity model |
| Discovery | Persona-Driven Search | Find content/people via self-match |
| Portability | Exportable Identity Graph | Reuse across tools & contexts |
| Control | Consent & Data Governance | Granular permissions, reversibility |
4. Use Cases & Applications
Personal
- Automated life journaling
- Mood and interest evolution tracking
- Digital memory and recall
- Identity gap analysis (who I think I am vs how I behave)
Creative & Professional
- Living portfolio of thought and taste
- Knowledge synthesis across years
- Career narrative and positioning
- AI-assisted self-review
Social & Discovery
- Find people “like me” or intentionally unlike me
- Build curated “For-You-Pages-of-Me”
- Explore communities through identity resonance
Research & Societal (Opt-in)
- Longitudinal cultural studies
- Ethical persona matching systems
- New models of identity portability
5. Technical Challenges
Architectural
- Cross-platform data ingestion variability
- API access volatility and rate limits
- Identity graph consistency over time
Operational
- Continuous consent management
- Secure storage of deeply personal data
- Explainable AI interpretation
Integration
- OAuth + export-based ingestion
- Heterogeneous data normalization
- Versioning of identity states
6. Risks & Mitigation Strategies
| Risk Category | Risk | Mitigation |
| Strategic | Misuse as surveillance or cloning tool | Strict consent, personal-only default |
| Ethical | Identity over-determinism | Narrative plurality, uncertainty framing |
| Regulatory | GDPR & platform compliance | User-owned data, revocation controls |
| Adoption | “Too abstract” for users | Progressive disclosure UX |
| Financial | High compute costs | Tiered features, local processing options |
7. SWOT Analysis
Strengths
- Deeply differentiated concept
- Strong narrative resonance
- Multi-sector adaptability
Weaknesses
- Abstract value proposition initially
- High trust requirement
- Complex onboarding
Opportunities
- Identity portability movement
- Creator economy tools
- Ethical AI leadership
Threats
- Platform lock-downs
- Data regulation shifts
- Misinterpretation by market
8. Role of AI, Data Usage, and Data Storage
This section defines how AI operates within the application, what it is allowed to do, how data is used, and how data is stored. It is written to align with the reflective, user-owned intent of the Personal Interaction Chronicle and to remain compatible with real-world platform, regulatory, and ethical constraints.
Role of AI in the Application
AI functions as an interpretive and reflective layer, not a decision-making authority. Its purpose is to help you see patterns, narratives, and trajectories within your digital interactions, without directing behavior or optimizing engagement.
Core AI roles include:
- Narrative construction
AI translates raw interaction data into readable journal entries, summaries, and timelines. These outputs focus on meaning and continuity rather than performance metrics. - Pattern and trend detection
AI identifies recurring themes, shifts in interests, rhythms of activity, and long-term changes across time. All insights are framed as probabilistic signals, not facts. - Identity modeling
AI maintains a versioned, evolving identity layer, sometimes referred to as a virtual self. This model reflects observed behavior and self-authored context, and it explicitly allows for contradiction and change. - Query and reflection support
AI enables natural-language exploration of your own data, such as asking what influenced a period of interest change or how creative focus evolved over time.
Guardrails applied to AI behavior:
- No prediction of future actions.
- No prescriptive recommendations.
- No hidden scoring, ranking, or profiling.
- No inference of sensitive personal attributes without explicit review and approval.
AI outputs always include confidence indicators and data coverage context, so uncertainty is visible rather than concealed.
Use of Data Within the Application
Data is treated as raw material for reflection, not as an asset for monetization or behavioral manipulation. You remain the data controller at all times.
Primary data uses:
- Transforming interaction logs into narrative and analytical views.
- Supporting identity continuity across time and platforms.
- Enabling personal search, recall, and comparison.
- Allowing export of personal identity artifacts and summaries.
Explicit exclusions by default:
- Private messages.
- Third-party data about other individuals.
- Covert enrichment from external data brokers.
- Secondary use for advertising, training third-party models, or resale.
AI processing is purpose-limited. Each transformation has a clear, user-visible reason tied to reflection, journaling, or identity coherence.
Data Storage Architecture
Data storage is designed around security, minimization, auditability, and reversibility.
Storage layers include:
- Encrypted raw data vault
Immutable copies of ingested data, stored in encrypted form. This layer exists to preserve provenance and enable re-interpretation as models improve. - Event and time-series store
Normalized interaction events structured for temporal analysis, such as frequency, recurrence, and evolution. - Identity and knowledge graph store
A graph-based representation of themes, entities, relationships, and identity states. Identity is versioned, never overwritten. - Derived feature store
Temporary or regenerable AI-derived signals such as embeddings, clusters, or summaries, always traceable back to source data. - Audit and consent log
A complete record of data ingestion, transformation, access, export, and deletion actions.
All storage layers support:
- End-to-end encryption.
- Granular retention controls.
- User-initiated deletion or cryptographic erasure.
- Clear separation between observed data and interpreted outputs.
Data Ownership and Control
You retain full ownership of your data and all derived artifacts. The application operates strictly as a processor acting on your instructions.
You can:
- Inspect what data exists and where it came from.
- See how AI used that data to generate each insight.
- Export your data and identity models in portable formats.
- Revoke consent at any time.
- Disable specific AI layers or inference types.
Incomplete or missing data is treated as a first-class condition. The system surfaces gaps clearly and avoids compensating with speculative inference.
Design Principle Summary
- AI reflects, it does not decide.
- Data explains, it does not score.
- Storage preserves history, not authority.
- Uncertainty is shown, not hidden.
This approach ensures the application remains a tool for understanding and agency, rather than surveillance or optimization disguised as insight.
9. Next Steps & Roadmap
Phase 1 — Reflection MVP
- Single-user journaling
- Limited platforms (e.g., Spotify + YouTube)
- Narrative outputs only
Phase 2 — Identity Layer
- Persona modeling
- Visual self-maps
- Query interface
Phase 3 — Discovery & Search
- Persona-based exploration
- Community matching
- Exportable identity objects
Phase 4 — Ecosystem Expansion
- Modular integrations
- Research partnerships (opt-in)
- Ethical governance board
Conclusion
The Personal Interaction Chronicle is not a product that tells you who you are.
It is a system that lets you see yourself, continuously, honestly, and on your own terms.
In an era where identity is increasingly inferred about us, this is an infrastructure for identity constructed with us.
It is slow, reflective technology—designed not to capture attention, but to return meaning.
Appendix A — Technical & Policy Foundations
Below is a formal Appendix designed to slot directly into the Vision Document you approved.
It is written in a policy-aware, systems-engineering voice, tightly aligned with the narrative intent of The Personal Interaction Chronicle, while being explicit about technical reality, constraints, and trade-offs.
A.1 Purpose of This Appendix
This appendix examines the technical, data acquisition, and policy dimensions underpinning The Personal Interaction Chronicle. It is intended to:
- Clarify what is technically feasible vs. aspirational
- Establish a data acquisition framework grounded in current platform realities
- Surface limitations, risks, and incomplete-data scenarios
- Define workarounds, mitigations, and design principles that preserve integrity despite constraints
This appendix is not a promise of total visibility—but a blueprint for responsible, resilient implementation under real-world conditions.
A.2 Data Acquisition Framework
A.2.1 Design Principles
- User Sovereignty First
All data acquisition is explicitly user-authorized, revocable, and transparent. - Progressive Fidelity
The system is designed to function meaningfully with partial data and improve incrementally. - Multi-Path Ingestion
No single platform or method is treated as a dependency of success. - Interpretive, Not Exhaustive
The Chronicle reflects patterns, not absolute truth.
A.2.2 Data Sources & Acquisition Pathways
| Pathway | Description | Strengths | Limitations |
| OAuth APIs | Direct platform authorization | Structured, real-time | Heavily restricted scopes |
| User Data Exports | GDPR/CCPA export files | High completeness | Episodic, non-real-time |
| Manual Imports | Documents, journals, CVs | High semantic value | User effort required |
| Event-Level Capture (Forward) | Opt-in tracking from start date | Clean data lineage | No historical recovery |
| Derived Signals | AI inference from sparse data | Works with gaps | Higher uncertainty |
Key Insight:
The Chronicle is not dependent on any single acquisition method. It is designed as a federated ingestion system.
A.2.3 Data Types Considered
- Interaction metadata (likes, saves, follows, listens)
- Temporal patterns (frequency, recurrence, intensity)
- Semantic artifacts (comments, playlists, titles, documents)
- Self-authored context (journals, annotations, reflections)
Explicitly Excluded by Default
- Private messages
- Third-party data about others
- Covert or inferred personal attributes without user review
A.3 Implementation Pathway
Phase 1 — Constrained Foundation
- Limited platform scope (e.g., Spotify, YouTube)
- Export-based ingestion
- Narrative journaling outputs only
Phase 2 — Hybrid Ingestion
- OAuth where permitted
- Manual + automated blending
- Identity graph v1
Phase 3 — Longitudinal Layer
- Time-series identity evolution
- Versioned personas
- Uncertainty annotations
Phase 4 — Ecosystem & Portability
- Exportable identity objects
- Third-party tool integration
- Research & enterprise opt-in layers
A.4 Policy & Regulatory Considerations
A.4.1 Core Regulatory Domains
| Domain | Relevance |
| GDPR / CCPA | Data access, erasure, portability |
| Platform Terms of Service | API scope and usage |
| AI Governance | Explainability, non-determinism |
| Data Ethics | Identity modeling boundaries |
A.4.2 Policy Stance
- User as Data Controller
- Chronicle as Data Processor
- No resale, profiling, or secondary use without explicit opt-in
- Clear separation between reflection tools and commercial layers
A.5 Limitations, Risks & Challenges
A.5.1 Incomplete Data Reality
Incomplete data is not an edge case—it is the default state.
Causes include:
- Platform restrictions
- Historical gaps
- Deleted or ephemeral content
- Asymmetric user behavior across platforms
A.5.2 Impact of Incomplete Data
| Impact Area | Consequence |
| Identity Modeling | Partial or skewed self-portrait |
| Pattern Detection | False absences or over-weighted signals |
| Narrative Output | Overemphasis on visible domains |
| User Trust | Misinterpretation risk |
A.6 Mitigations & Workarounds
A.6.1 Technical Mitigations
- Confidence scoring per insight
- Explicit data coverage indicators
- Temporal weighting to avoid recency bias
- Multi-source triangulation
A.6.2 UX & Narrative Mitigations
- Language of probability, not certainty
- “This may reflect…” framing
- User annotations to override or contextualize AI interpretation
- Visual gaps shown, not hidden
A.6.3 Governance Mitigations
- Audit logs of data sources used
- Explainable insight generation
- Ability to “turn off” inference layers
- Clear distinction between observed vs interpreted data
A.7 Risk Register Summary
| Risk | Severity | Mitigation |
| Platform API withdrawal | High | Export-first strategy |
| Over-interpretation of self | Medium | Uncertainty tags |
| Privacy breach | High | Encryption, minimization |
| Identity determinism | Medium | Narrative plurality |
| Regulatory shifts | Medium | Modular compliance layer |
A.8 Strategic Insight: Embracing Imperfection
The Chronicle does not fail because data is incomplete.
It fails only if it pretends completeness.
By treating gaps as first-class citizens—visible, contextualized, and narratively framed—the system reinforces trust and intellectual honesty.
In this sense, incompleteness becomes a feature, not a flaw:
- It invites reflection
- It resists false authority
- It keeps the human in the loop
Below are two technical architecture diagrams + an end-to-end data flow, designed for The Personal Interaction Chronicle (cross-platform self-twin / living journal + persona layer). This aligns with your ingestion constraints (OAuth + exports + optional imports) and your emphasis on narrative + analytics.
1) Technical Architecture Diagram (Logical / Component View)
flowchart TB
%% — SOURCES —
subgraph S[Data Sources]
A1[Platform APIs\nOAuth scopes\nYouTube/Spotify/etc.]
A2[User Data Exports\n(GDPR/CCPA archives)]
A3[Manual Imports\nDocs/CV/Writing\nNotes]
A4[Forward Capture\nBrowser/App Extension\n(Opt-in)]
end
%% — INGESTION —
subgraph I[Ingestion & Acquisition Layer]
B1[Connector Hub\nOAuth + Token Vault]
B2[Export Ingest Service\nUpload + Parse + Validate]
B3[Import Gateway\nFile upload + Text extraction]
B4[Event Collector\nForward telemetry\n(privacy-preserving)]
B5[Consent & Policy Gate\nScopes, purpose,\nretention rules]
end
%% — PROCESSING —
subgraph P[Processing & Intelligence Layer]
C1[Normalization & Schema Mapper\nCommon event model]
C2[PII/Sensitive Data Classifier\nRedaction + minimization]
C3[Identity Resolution\nAccount link + dedupe]
C4[Enrichment\nTime, topics,\nsentiment (bounded)]
C5[Uncertainty Engine\nCoverage + confidence scores]
C6[Personal Knowledge Graph Builder\nEntities, themes, relationships]
C7[Journal/Narrative Generator\nChronicle entries + summaries]
C8[Insights Engine\nPatterns, clusters,\ntrendlines]
end
%% — STORAGE —
subgraph D[Data Stores]
D1[(Encrypted Raw Vault\nImmutable ingest copies)]
D2[(Event Store\nTime-series interactions)]
D3[(Graph DB\nPersona/PKG)]
D4[(Feature Store\nEmbeddings + aggregates)]
D5[(Audit Log\nEvery access + transform)]
end
%% — EXPERIENCE / API —
subgraph X[Experience & Delivery Layer]
E1[Chronicle UI\nTimelines, mood/interest maps]
E2[Query Interface\nAsk-your-self engine]
E3[Export/Portability\nIdentity object + reports]
E4[Developer/API Gateway\nScoped access tokens]
end
%% — GOVERNANCE —
subgraph G[Governance & Security (Cross-cutting)]
F1[Key Mgmt / KMS\nRotation + envelope encryption]
F2[RBAC/ABAC\nRole + attribute based access]
F3[Data Retention & Deletion\nUser controls + timers]
F4[Model Guardrails\nNo-determinism,\nexplainability]
F5[Compliance Toolkit\nDPIA pack, consent receipts]
end
%% — FLOWS —
S –> I
A1 –> B1
A2 –> B2
A3 –> B3
A4 –> B4
B1 –> B5
B2 –> B5
B3 –> B5
B4 –> B5
B5 –> C1
C1 –> C2 –> C3 –> C4 –> C5
C5 –> C6 –> C7 –> E1
C6 –> C8 –> E1
C7 –> E2
C8 –> E2
E3 –> E4
%% Storage writes
C1 –> D1
C1 –> D2
C6 –> D3
C4 –> D4
B5 –> D5
C2 –> D5
E2 –> D5
E3 –> D5
%% Governance connections
G -. governs .- I
G -. governs .- P
G -. governs .- D
G -. governs .- X
What this diagram encodes
- Your “platforms as constrained feeds” assumption (OAuth scopes + export-first fallback).
- The Chronicle’s dual output modes: Narrative (Journal) + Analytic Mirror (Insights/Graph).
- A built-in Uncertainty Engine so incomplete data is explicit rather than silently “filled in.”
2) Data Flow Diagram (Lifecycle / Step-by-Step)
sequenceDiagram
autonumber
participant U as User
participant UI as Chronicle UI
participant CG as Consent & Policy Gate
participant IN as Ingestion Services
participant PR as Processing & Intelligence
participant ST as Stores (Vault/Event/Graph/Features)
participant AI as Narrative + Insight Engines
participant AU as Audit/Compliance Log
U->>UI: Connect platform / upload export / import docs
UI->>CG: Request consent (scopes, purposes, retention)
CG->>AU: Record consent receipt + policy snapshot
CG–>>UI: Approved scopes + constraints
UI->>IN: Ingest (OAuth pulls / export parse / file import / forward capture)
IN->>ST: Write immutable raw copies (Encrypted Vault)
IN->>AU: Log ingestion events + source metadata
IN->>PR: Normalize to Common Event Model
PR->>PR: Classify sensitive data + redact/minimize
PR->>AU: Log transforms + redaction decisions
PR->>ST: Append to Event Store (time-series)
PR->>ST: Update Graph DB (entities/themes/links)
PR->>ST: Update Feature Store (embeddings/aggregates)
PR->>AI: Compute patterns + generate Chronicle entries
AI->>ST: Store journal entries + insight artifacts
AI->>PR: Compute coverage/confidence (Uncertainty Engine)
UI->>AI: User query (“What shaped my interests this month?”)
AI->>ST: Retrieve events/graph/features (scoped)
AI–>>UI: Answer + confidence + data coverage map
UI->>AU: Log access + export + user actions
U->>UI: Export / delete / revoke
UI->>CG: Execute retention or deletion policy
CG->>ST: Delete/cryptoshred per policy
CG->>AU: Log proof-of-action
3) Key Data Contracts (So the System Stays Coherent)
Common Event Model (minimum viable schema)
- event_id, source_platform, account_id
- event_type (view/like/comment/save/play/share/follow)
- timestamp, content_ref (URL/ID when permitted)
- text_payload (optional; redacted by policy)
- signals (topics/sentiment bounded, confidence)
- provenance (OAuth/export/manual/forward-capture)
- coverage_flags (missing fields, scope limits)
Persona / Graph Primitives
- Entities: topics, creators, media items, concepts, people (as allowed)
- Edges: interacted-with, co-occurs-with, evolves-into, contradicts, amplifies
- Time: versioned snapshots (identity is never a single “truth”)
4) Where Incomplete Data Shows Up (and How We Surface It)
Common incompleteness causes
- OAuth scopes don’t include watch history / full interaction logs
- Exports vary in structure and completeness across platforms
- Deleted/ephemeral content or account history gaps
- Multi-account identity resolution failures
System responses (architectural)
- Coverage Map in UI (per platform / per time range / per event type)
- Confidence scoring per insight + traceable provenance
- Triangulation logic (derive patterns only when multiple signals agree)
- User annotation to correct narrative drift (“this month was atypical because…”)
This prevents the system from presenting a false totality, protecting trust.
5) Suggested “Implementation Pathway” (Architecture-first MVP)
MVP (8–12 weeks, realistic)
- Export ingestion for 1–2 platforms
- Common Event Model + encrypted vault + audit log
- Narrative journaling (daily/weekly) with coverage indicators
- Basic timeline + interest clusters
V1
- Add Graph DB persona layer
- Add query interface
- Add forward capture for clean future data
V2
- Expand connectors where scopes allow
- Portability/export of identity objects
Further considerations create :
- a deployment architecture (cloud components, network boundaries, secret management),
- a zero-trust security model for “personal data vault + local-first option,”
- or a DPIA-style data flow inventory (tables listing every field, purpose, retention, lawful basis).
Appendix Closing Note
This appendix establishes a critical truth:
The Personal Interaction Chronicle is not a surveillance system, nor a total mirror—it is a negotiated, evolving conversation between a person and their digital traces.
Its technical and policy foundations are intentionally conservative, modular, and ethically biased toward restraint.
That restraint is what makes the vision viable.



{kind=link}
{kind=link}
{kind=link}
{kind=link}