
A Critical Analysis of Architecture, Industry Solutions, and the Future of Grounded Intelligence
Preamble
There is a paradox at the heart of modern AI deployment that the industry has not yet fully reckoned with.
We now possess language models of extraordinary capability systems that can reason across disciplines, synthesise complex information, generate code, draft legal arguments, and hold conversations that feel genuinely intelligent. Yet these same systems, when deployed into the living, breathing environments of enterprise operations, clinical workflows, financial markets, and physical infrastructure, suffer from an affliction so fundamental it borders on the architectural: they do not know what time it is.
Not literally, of course. An LLM can tell you today’s date if you pass it in the prompt. The deeper problem is subtler and more consequential. These models were trained on frozen datasets. Their knowledge, however vast, ended at a fixed point. Every interaction they hold every decision they support, every document they generate, every action they take is conducted from within a sealed vault of historical understanding, while the world outside continues to change at a pace that makes yesterday’s context genuinely dangerous to act upon today.
This is the structural mismatch that defines applied AI in 2026. It is not a problem of model intelligence. It is a problem of grounding.
This article is addressed to the professional who has encountered this problem in practice: the enterprise architect who has built a production AI system only to discover that it hallucinates facts that were accurate eighteen months ago; the developer who has watched an agentic workflow confidently execute on stale policy; the researcher who understands, at a technical level, why the transformer architecture makes this problem intrinsic rather than incidental. It is also addressed to the individual practitioner and SME who is beginning to wonder whether the AI tools they are adopting are actually connected to the world they inhabit.
What follows is an analysis of persistent memory and the Real-World Context Bridge a structured framework for understanding and designing the bridging infrastructure that connects static model intelligence to dynamic reality. We will examine the architecture, critique its current state, survey the industry solutions emerging to address it, assess the research frontiers, and make a considered judgment on the most consequential open question: will persistent memory eventually be integrated natively into the model itself, or will the external bridge remain a permanent fixture of AI system design?
The answer, as we will show, is both and understanding why matters enormously for every decision about how to build AI systems today.
YouTube
As usual some artifacts: AI bridge Table: Reference Documents and Short Descriptions
| Document Name | Short Description |
| bridge.docx | Defines what a bridge is in AI, covering model, data, modality, integration, and human bridges. Introduces the Grounded Context Bridge, explains sensing, curation, verification, tool use, governance, and criteria for modelling the real world. Includes architectural patterns and use‑case examples. |
| Bridging Static LLMs and the Dynamic Real World.docx | A structured paper explaining why static LLMs need external context systems. Introduces the Real‑World Context Bridge (RWCB), its components, constraints, and value. Includes a full architecture, use cases, and analysis of cloud vs local LLM deployment. |
| Diagrams.docx | Contains five text‑based system diagrams: workflow, modular architecture, sequence diagram, data‑flow diagram, and systems‑engineering block diagram. Also includes a unified master diagram and narrative walkthrough. |
| Enterprise deployment Implications Short Medium and Long Term.docx | Analyses enterprise implications of RWCB adoption across short, medium, and long‑term horizons. Covers cost, governance, hybrid cloud/on‑prem strategies, memory governance, regulatory pressures, and strategic positioning. |
| Formal architecture specification.docx | A TOGAF‑style formal specification of the RWCB architecture. Defines purpose, assumptions, subsystems, design decisions, risks, use‑case patterns, and technology mapping. |
| Future trends in multimodal memory integration for LLMs 2026.docx | A research synthesis on multimodal memory trends: Memory Bear, Titans/MIRAS, CoMEM, multimodal temporal graphs, federated memory, and AI‑native memory hardware. Maps these trends to RWCB subsystems. |
| Non Enterprise Implications The Individual Developer Researcher and SME Lens.docx | Analyses RWCB implications for individuals, developers, researchers, and SMEs. Covers local vs cloud LLM economics, hardware tiers, personal RWCB design, and long‑term AI sovereignty. |
| Persistent Memory and the Real-World Context Bridge.docx | A scholarly article synthesising all documents into a unified analysis. Provides critique, use cases, research directions, governance issues, and the future of persistent memory in AI. |
| Practical implementation guide for persistent memory in multiagent systems.docx | A technical implementation guide for multi‑agent memory systems. Covers memory taxonomies, coordination patterns, |
Part I: The Structural Mismatch : Why This Problem Cannot Be Model-Solved Away
The Frozen Vault Problem
To understand why real-time persistent memory matters, it is necessary to be precise about what LLMs actually are and what they are not.
A large language model is, at its core, a compressed statistical representation of a corpus of human knowledge up to a given date. The model’s weights — the billions of numerical parameters that encode its understanding of language, logic, and the world — are fixed at training time. They do not update when you interact with the model. They do not change when something in the world changes. They are, in a deep architectural sense, historical artefacts that happen to generate remarkably useful outputs.
The context window the text that a user passes to the model in a given interaction is the only real-time input the model receives. And context windows, however large they have become (modern frontier models support two million tokens or more), are ephemeral. They exist for one session and then are gone. There is no memory of what happened last Tuesday, no awareness of the policy that changed last month, no knowledge of the incident that occurred last night.
This creates three failure modes that are not edge cases but structural certainties for any serious enterprise deployment.
The first is temporal hallucination: the model asserts facts that were accurate at training time but have since changed, with no awareness that anything has changed. A model trained in early 2024 confidently discussing regulatory requirements that were revised in late 2025 is not being stupid it is being faithful to its training data. It simply cannot know what it does not know.
The second is institutional amnesia: the model treats every session as its first, with no continuity of context across interactions. In human organisations, the accumulated memory of past decisions, past errors, past client interactions, and past operational state is the substrate on which intelligent action is built. AI systems without persistent memory strip this substrate away entirely.
The third is authority collapse: without temporal awareness, a model cannot distinguish between a superseded policy and a current one, between a contract clause that was amended and one that was not, between data from a system that has since been decommissioned and data from a live source. All information in the context is, from the model’s perspective, equally authoritative. These are not problems that disappear with larger models or longer context windows. They are intrinsic to the architecture.
Why Scaling Alone Cannot Fix This
The natural response to limitations of this kind is to assume that more scale will resolve them. Bigger models, longer contexts, more training data surely these address the grounding problem over time?
They do not, and the reasons are important to understand.
Longer context windows reduce but do not eliminate session amnesia. You can pass more history into a given interaction, but at unsustainable cost. Enterprise teams that have treated the context window as their primary memory mechanism are discovering that inference costs for high-volume workflows can reach extraordinary levels, documented cases in production suggest figures approaching seven figures monthly at scale. Brute-force token expansion is not a viable strategy.
More training data helps with general knowledge coverage but cannot solve the private data problem. An organisation’s proprietary contracts, internal policies, customer records, and operational state will never appear in public training data. The model cannot know what it was not trained on, regardless of how much of everything else it has learned.
More frequent retraining reduces the knowledge gap but introduces its own problems cost, consistency, governance, and the risk that the model’s behaviour changes in unpredictable ways as its weights are updated. And even a model retrained yesterday has no knowledge of what changed today.
The conclusion, uncomfortable as it may be for those who have invested in model-centric strategies, is this: the capability ceiling for enterprise AI in 2026 is not model quality. It is memory architecture.
Part II: The Real-World Context Bridge: Architecture and Critique
References: AI Bridge and Models
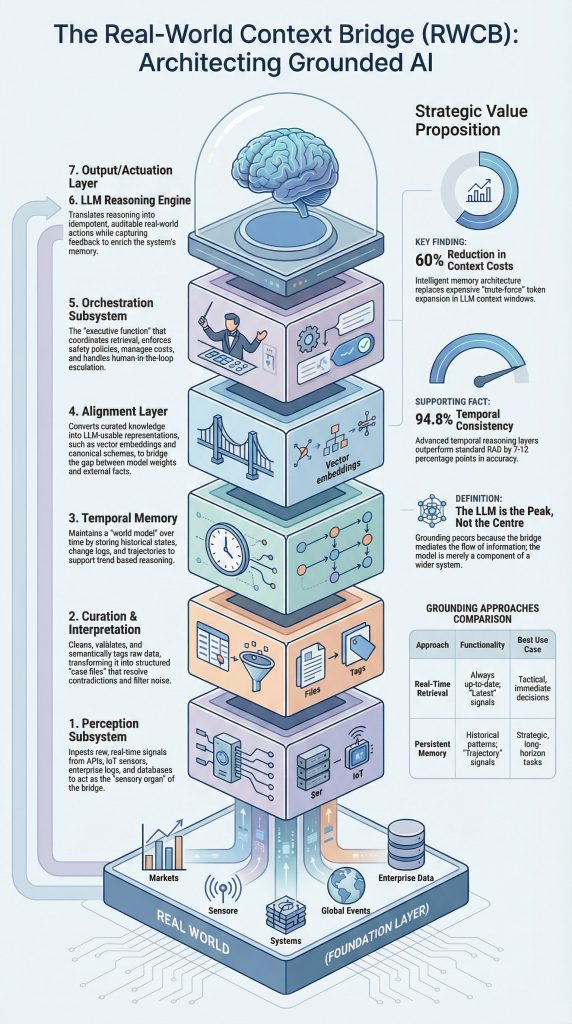
A Seven-Layer Architecture
The Real-World Context Bridge (RWCB) is a structured framework for solving the grounding problem. It is a layered infrastructure stack that sits between a static LLM and the dynamic external world, mediating the flow of information in both directions. It is not a product it is an architecture pattern, analogous in its role to how enterprise integration middleware mediated between legacy systems and modern applications in an earlier era of technology.
The RWCB as formally specified operates across seven discrete subsystems, each with defined responsibilities and interfaces.
The Perception Subsystem : is the sensory organ of the bridge. It connects to the external signals relevant to the deployment context APIs, databases, IoT streams, event buses, news feeds, internal document stores, calendars, ticketing systems. It is responsible for ingestion and normalisation: converting raw signals from heterogeneous sources into a standardised internal representation. The design principle here is event-driven ingestion where possible, with batch processing reserved for heavy analytics workloads. Critically, the perception subsystem is not a simple data pipeline ,it is a curated connection layer that determines what signals the system is even permitted to observe.
The Curation and Interpretation Subsystem: is where raw signals become structured knowledge. It applies cleaning, validation, semantic tagging, and knowledge graph mapping to the normalised inputs from the perception layer. This is where the real intellectual work of bridging happens where the difference between web search and a grounded context engine becomes concrete. A web search returns a ranked list of documents. The curation subsystem transforms retrieved information into a structured, validated, semantically enriched case file that the LLM can reason over with appropriate epistemic confidence. Rule-based and ML-based curation are combined, with explicit data quality SLAs defining what constitutes acceptable signal quality.
The Temporal Memory Subsystem : is arguably, the most architecturally distinctive component of the RWCB. Its responsibility is to maintain time-aware state not merely storing information, but tracking how information changes over time, maintaining timelines, and supporting temporal reasoning. This subsystem distinguishes between hot storage (recent, high-access context), warm storage (relational and structured historical data), and cold storage (archival, low-access historical records). This tiering is critical for cost management: maintaining every piece of retrieved information in high-performance vector stores would be ruinously expensive; intelligent lifecycle management across storage tiers makes the system economically viable.
The Alignment Subsystem: translates the structured world model maintained by the temporal memory layer into representations that the LLM can consume. This involves embedding generation, schema alignment, and context normalisation ensuring that the gap between the world model’s representation and the model’s internal representations is bridged in a way that enables grounded reasoning rather than superficial pattern matching. This subsystem is currently the most active area of research and the most rapidly evolving component of the stack.
The Orchestration Subsystem: is the conductor. It coordinates retrieval requests, memory queries, tool invocations, policy enforcement, and LLM calls according to explicit agent frameworks with pluggable tools and a policy engine. The orchestration layer is where safety constraints are operationalised: it is the last line of defence before information reaches the model, and it is the first point of control over what the model is permitted to do with that information.
The LLM Reasoning Engine: is the model itself treated, in the RWCB architecture, not as the system but as a component of the system. This framing is important: the model performs grounded reasoning using context provided by the layers above, but it is not the authority on what context is appropriate, what sources are trustworthy, or what actions are permitted. Those determinations are made by the bridge, not the model.
The Output and Actuation Layer : connects the model’s outputs back to the external world executing decisions in enterprise systems, triggering workflows, updating records, and capturing feedback for system improvement. Critically, the actuation layer implements idempotent, auditable actions with explicit rollback and compensation patterns. The system must be able to demonstrate, after the fact, exactly what it did, why, and on what basis.
The Architecture’s Strengths
The RWCB architecture has several significant strengths that distinguish it from simpler approaches to the grounding problem.
Its modularity is its most important property. Each subsystem has defined responsibilities and explicit interfaces. This means that individual components can be upgraded, replaced, or pointed at different infrastructure without requiring redesign of the whole stack. As the industry transitions toward hybrid deployment models cloud for burst capacity and general reasoning, on-premise for sensitive and regulated workloads this modularity enables that transition without re-architecture.
Its explicit separation of concerns between model, memory, and reality is architecturally sound and practically important. By treating these as distinct products rather than aspects of a single system, the RWCB creates clear accountability boundaries: the model owns reasoning, the bridge owns context governance, and the external world owns ground truth. This separation is what makes audit, compliance, and governance tractable.
Its treatment of human oversight as a first-class design option not an afterthought reflects a mature understanding of where AI systems currently sit in the trust hierarchy. The RWCB specification explicitly requires human-in-the-loop as a configurable option for material decisions, and in regulated domains, as a mandatory constraint.
The Architecture’s Weaknesses
A thorough critique must also identify where the RWCB specification, as currently documented, falls short.
The most significant gap is the absence of a principled forgetting and memory lifecycle model. The specification defines storage tiers but does not specify retention policies, decay functions, or the triggers for moving information between tiers. This is not a minor omission it is a fundamental architectural question. Memory systems that retain everything indefinitely become computationally intractable. Memory systems that discard too aggressively lose the longitudinal context that makes temporal reasoning possible. The research literature, particularly MemoryLLM’s exponential decay mechanisms and MemoryBank’s spaced-repetition approach, provides the mathematical tools for addressing this; the RWCB specification needs to incorporate them explicitly.
The second gap is the absence of causal chain modelling in the temporal memory and alignment subsystems. Current state-of-the-art temporal RAG systems E2RAG, DyG-RAG, Memory-T1 achieve 94.8% temporal consistency by combining causal chain modelling with temporal entity recognition, improving over standard RAG by seven to twelve percentage points. The RWCB’s temporal memory subsystem, as specified, supports time-bounded queries and trend reasoning but does not explicitly model the causal relationships between temporal events. This limits the system’s ability to reason about why things changed, not merely that they changed.
The third gap is the absence of a standardised evaluation protocol. How does one measure bridge performance? What constitutes a successful grounding operation? The specification is largely silent on measurement, which is a significant practical obstacle to adoption. The emerging benchmarks TIME, ChronoQA, TimeShift provide the scaffolding for this; the RWCB needs a formal evaluation suite built on these tools.
Part III: The Research Frontier — What the Lab Is Building
Memory Bear and Cognitive Architectures
The most intellectually significant recent development in persistent memory research is the emergence of cognitively grounded memory architectures systems that draw explicitly on human cognitive science to design more effective AI memory.
The Memory Bear architecture (arXiv:2512.20651, published January 2026) represents the current state of the art. It integrates the ACT-R cognitive architecture a computational theory of human cognition developed at Carnegie Mellon with the Ebbinghaus forgetting curve into a three-layer system. The storage layer processes text, audio transcriptions, images, and structured records into semantically aligned memory units with emotional-salience weighting, enabling the system to prioritise genuinely important information over incidental context. The orchestration layer performs periodic offline memory reorganisation a “sleep-like” consolidation process that integrates new information with existing long-term knowledge. The forgetting engine applies base-level activation formulas with controlled decay, maintaining memory efficiency over long time horizons. Consider some (not all i.e persistent memory) in Toward a Unified Cognitive Foresight (AI) Architecture: Creating a Governed, Embodied, Multi Agent Intelligence System
When benchmarked against Mem0, MemGPT, and LangChain memory the current production standard Memory Bear achieves superior accuracy alongside a 90% reduction in token usage through intelligent semantic pruning, a 60% reduction in computation cost, and a 70% reduction in off-topic responses in long-horizon dialogues. These are not marginal improvements. They represent a qualitative shift in what is achievable with persistent memory architectures.
The implications for the RWCB’s temporal memory subsystem are direct: the forgetting engine is the precise mechanism the specification currently lacks, and the emotional-salience weighting offers a principled basis for the retention policy that the architecture needs.
Google Titans: Native Long-Term Memory in Transformers
Published in December 2025, Google’s Titans architecture represents the most significant advance in the question of whether persistent memory can be integrated natively into the transformer itself rather than remaining an external layer.
Titans introduces a neural long-term memory module implemented as a multi-layer perceptron ; not a fixed vector matrix , that actively updates its own parameters as data streams in, at test time, without retraining the main model weights. The key mechanism is a surprise metric: the system detects large divergences between its current memory state and new input, selectively writing only novel or anomalous information to long-term storage. This is mathematically analogous to the amygdala’s role in prioritising emotionally salient memories a convergence with the cognitive science approach that Memory Bear takes from a different direction.
Titans further incorporates momentum (capturing relevance across adjacent surprising tokens, not just individual ones) and an adaptive weight decay gate that manages finite memory capacity over extremely long sequences. The empirical results are striking: Titans outperforms GPT-4 on BABILong (a long-context reasoning benchmark), scales to context windows exceeding two million tokens, and does so with linear rather than quadratic inference complexity.
The MIRAS theoretical framework, published alongside Titans, unifies all sequence models under a common framework of four design choices: memory architecture, attentional bias, retention gate, and memory algorithm. This is significant not merely as a theoretical contribution but as a design vocabulary that the field has been lacking a shared language for comparing and composing memory architectures that will accelerate both research and implementation.
CoMEM and the Multimodal Frontier
Research published in May 2025 (arXiv:2505.17670) introduces CoMEM ; Continuous Memory for Vision-Language Models with an insight that simplifies the multimodal memory problem considerably. A vision-language model can serve as its own memory encoder, reusing its own continuous embeddings to represent external multimodal knowledge without additional training. A lightweight Q-Former controls the compression rate, and the system supports plug-and-play integration with existing VLMs.
This matters for the RWCB’s alignment subsystem because it suggests that, rather than requiring separate embedding models for text, image, and audio modalities, a unified continuous embedding space that a VLM can natively read and write becomes achievable. The practical implication is a significant simplification of the multimodal alignment layer : one unified encoder rather than a heterogeneous collection of modality-specific pipelines.
In 2026, multimodality is not a differentiating feature it is the baseline expectation. Any leading model is expected to reason natively across text, image, audio, and video. This means the RWCB’s temporal memory and alignment subsystems need explicit multimodal encoding pipelines and cross-modal retrieval indexes, not merely text-centric vector stores. The early adopters of cross-attention-based multimodal integration are reporting 30% increases in task efficiency; modular memory systems that compartmentalise multimodal context are showing 20% improvements in processing speed for complex reasoning tasks.
MemoryLLM and Native Memory Pools
Wang et al.’s MemoryLLM research demonstrates that it is architecturally feasible to embed a persistent, self-updatable memory pool directly within transformer layers. The system fuses a learnable fixed-size memory pool with per-layer activations via self-attention, enabling real-time knowledge injection without retraining model weights. MemoryLLM+ extends the effective context window from 20,000 to 160,000 tokens with less than 5% GPU overhead, and empirical testing confirms long-term retention persisting across nearly one million memory updates with no measurable degradation.
This research, combined with the Titans architecture, establishes that native persistent memory is not merely a theoretical possibility but an empirically demonstrated capability. The question has shifted from “can it be done?” to “what are the tradeoffs, and who should own the memory?”
Part IV: The Industry Landscape: What Is Actually Being Built
The Commercial Memory Stack
The commercial AI memory market in 2026 is characterised by rapid fragmentation and early consolidation. Several categories of solution have emerged.
Memory-as-a-Service providers offer managed persistent memory layers that sit above any LLM. Mem0, one of the leading players in this space, provides a hierarchical memory system with explicit user, session, and agent memory tiers, accessible via API. Its integration with LangChain, LlamaIndex, and OpenAI’s function calling ecosystem makes it the path of least resistance for developers building memory-aware applications on existing infrastructure. Benchmark comparisons against MemoryBank and A-MEM show competitive performance on long-horizon dialogue tasks, though the Memory Bear research demonstrates that cognitively grounded architectures can substantially outperform first-generation commercial offerings.
Orchestration frameworks with memory integration LangChain, LlamaIndex, CrewAI, AutoGen have all moved to include persistent memory primitives in their core offerings. LangChain’s memory abstraction supports multiple backends (in-memory, Redis, PostgreSQL, vector stores) with a consistent interface. LlamaIndex’s memory components are particularly strong on the retrieval side, offering sophisticated chunk-level and document-level retrieval with temporal indexing. These frameworks handle the orchestration and alignment layers of the RWCB but leave the perception, curation, and temporal memory subsystems to the implementer.
Vector database providers: Pinecone, Weaviate, Qdrant, Chroma are the default infrastructure for the semantic memory layer. Each has evolved significantly: namespace-based access control for multi-tenant deployments, hybrid search combining dense and sparse retrieval, and increasingly sophisticated metadata filtering including temporal ranges. However, vector databases are retrieval infrastructure, not memory architecture. They answer the question “what is most similar to this query?” but not “what should I remember, for how long, and how should I forget?”
OpenAI’s native memory deserves specific attention as the first commercial production deployment of persistent memory as a first-class platform feature. Introduced in 2025 and expanded in early 2026, OpenAI’s memory system maintains explicit user preferences and context across sessions, supports manual memory management, and provides enterprise controls for memory governance. It represents the first instance of a frontier model provider treating memory as part of the product rather than an external concern. The implications for the RWCB’s native-versus-external debate are significant, and we will return to them.
Anthropic’s Model Context Protocol (MCP) is the most structurally interesting development in the integration layer. MCP is an open standard for connecting LLMs to external tools, data sources, and memory systems through a consistent interface. It addresses precisely the perception subsystem of the RWCB the layer responsible for connecting the bridge to external signals. By standardising the connector protocol, MCP enables a marketplace of perception layer integrations that any MCP-compatible model can consume. It is, in effect, an open protocol for the lowest layers of the RWCB stack.
Cognee and Structured Knowledge Integration
Cognee, an open-source knowledge graph integration layer designed for use with Claude and other LLMs, represents a more architecturally ambitious approach to the memory problem. Rather than treating memory as a retrieval problem (finding relevant documents) or a storage problem (persisting conversation history), Cognee treats it as a knowledge engineering problem: how do you build a structured, queryable knowledge graph that captures the relationships between entities, facts, and events in a way that supports genuine reasoning rather than similarity-based retrieval?
This approach is more aligned with the RWCB’s curation and interpretation subsystem than with standard vector database deployments, and it suggests a direction for the field that may prove more durable than RAG-centric architectures for complex reasoning tasks.
Temporal RAG: The Current Production Standard
For enterprises deploying AI systems that need to reason about time, Temporal RAG retrieval-augmented generation with temporal awareness is the current production standard. Systems like E2RAG and DyG-RAG extend standard RAG with causal chain modelling and temporal entity recognition, achieving the 94.8% temporal consistency cited earlier. These systems understand that a document from 2023 and a document from 2026 discussing the same regulation may contradict each other, and that the contradiction should be resolved in favour of the more recent source unless there is evidence that the earlier source is authoritative for a different reason.
The practical gap between standard RAG deployments (the majority of enterprise AI deployments today) and Temporal RAG (the current state of the art) is substantial. Organisations still treating RAG as a differentiator are behind the curve; Temporal RAG is the baseline for any deployment where information has a meaningful shelf life.
Part V: Practical Use Cases: Where the Bridge Earns Its Keep
The Knowledge Worker Assistant
The highest-value, lowest-risk application of the RWCB pattern is the knowledge worker assistant with longitudinal memory. This is an AI system that maintains a coherent, evolving picture of a knowledge worker’s professional context their current projects, their past decisions, the documents they have worked with, the clients they have engaged, the regulatory frameworks relevant to their domain and uses that picture to provide genuinely contextualised assistance.
Without persistent memory, an AI assistant is a sophisticated autocomplete: brilliant in a single session, amnesiac between them. With persistent memory implemented at the RWCB level, the assistant becomes something qualitatively different: a professional partner that builds, over time, an understanding of the user’s work that a new human colleague would take months to develop.
The technical implementation for this use case follows the RWCB pattern closely. The perception subsystem connects to the user’s document repositories, calendar, email (with appropriate consent and data governance), and any relevant external knowledge sources. The curation layer extracts entities, relationships, and temporal context from ingested documents. The temporal memory layer maintains a structured timeline of professional context. The alignment layer translates this into retrievable context for each interaction. The orchestration layer applies role-based access controls and session-specific retrieval policies. The result is an assistant that can say, accurately: “Based on the approach you took in the Martinez engagement last quarter, and given that the regulatory framework has since been updated in these specific ways, here is what I would suggest…”
This use case is available today with existing tools. LangChain or LlamaIndex for orchestration, a vector database for semantic memory, a relational database for episodic memory, and OpenAI or Anthropic APIs for reasoning this stack, implemented carefully, delivers a meaningful approximation of the knowledge worker assistant. The RWCB architecture provides the design vocabulary for doing it rigorously rather than ad hoc.
Financial Services: Real-Time Market Context
In financial services, the grounding problem is acute because the cost of acting on stale information is immediately quantifiable and potentially catastrophic. A trading assistant that does not know about a central bank announcement made this morning, a compliance system that is unaware of a regulatory change that took effect last week, or a risk management tool that is reasoning from pre-crisis market data these are not hypothetical failure modes. They are the inevitable consequence of deploying ungrounded AI into environments where information has a very short shelf life.
The RWCB pattern for financial services deploys with a perception layer connected to market data feeds (Bloomberg, Reuters), regulatory update streams, and internal risk systems. The curation layer applies financial ontologies and temporal indexing to ensure that market events are understood in their temporal context a rate decision matters differently depending on what preceded it. The temporal memory layer maintains time-series representations of market state, regulatory state, and firm-specific risk exposure. Human-in-the-loop gates are mandatory for material decisions.
JPMorgan’s deployment of AI into document review and research synthesis, Goldman Sachs’ use of AI for market commentary, and BlackRock’s Aladdin platform’s integration of AI into portfolio analytics all represent early-stage deployments of what will eventually be full RWCB implementations. The industry is at stage 3-4 of the five-stage maturity framework governance and early temporal memory with full implementation emerging in the medium term.
Healthcare: Longitudinal Patient Context
Healthcare represents perhaps the most ethically demanding application of persistent memory in AI systems, and therefore the most instructive test case for the RWCB architecture’s governance properties.
The value proposition is clear: an AI system that maintains longitudinal patient context across encounters, clinicians, and institutions can provide genuinely continuous care support flagging drug interactions against a complete medication history, identifying patterns in symptoms that only become visible across a long timeline, and ensuring that clinical decisions are made with full contextual awareness rather than the fragmented view that characterises most current healthcare IT systems.
But the governance requirements are correspondingly demanding. The RWCB’s human-in-the-loop requirement is not configurable in this context it is mandatory. The temporal memory subsystem must maintain longitudinal context while complying with data retention, deletion, and consent requirements that vary by jurisdiction and patient preference. The curation subsystem must apply clinical ontologies and validation rules that govern what the model is and is not permitted to present as clinical guidance.
The bridge, in this context, is both a constraint and a referral system: hard guardrails prevent the model from acting on incomplete information, while soft routing escalates complex cases to specialist workflows. This is the RWCB at its most architecturally mature a system that knows not only what it knows but what it does not know, and that responds to the limits of its knowledge with appropriate humility and escalation rather than confident confabulation.
Multi-Agent Coordination: The New Frontier
The most technically demanding application of the RWCB pattern is multi-agent coordination systems in which multiple AI agents work in parallel, each with specialised roles, sharing a common memory infrastructure. This is where the memory problem becomes hardest, because memory structures that optimise individual agents do not automatically support coordination.
The key architectural primitive that multi-agent systems require and that single-agent frameworks do not provide is consensus memory: a verified, committed store of outputs that the whole agent team has ratified. Without it, multi-agent systems produce contradictory outputs because no agent has authoritative write access to the shared record.
The production pattern for multi-agent memory architecture follows a role-scoped access model: each agent has defined read scope (what it can retrieve), write scope (what it can store), and isolation boundary (what is private versus shared). An analyst agent might read from a shared semantic store and write to a consensus memory layer; a reviewer agent reads from the consensus store and writes only to a committed output store. The asymmetry is intentional: it creates a directed flow from tentative to authoritative, preventing the circular consistency failures that plague naive multi-agent memory implementations.
The 2026 statistic that 67% of enterprise AI deployments planned memory systems, compared to just 12% in 2025, reflects the acceleration of multi-agent deployment and the consequent recognition that memory architecture is the constraint, not model capability.
Part VI: Enterprise Implications ; Short, Medium, and Long Term
Short Term: 2026
The most urgent short-term implication for enterprise AI teams is architectural and financial simultaneously.
Enterprises still treating the context window as their primary memory mechanism are on an unsustainable cost trajectory. Inference costs for high-volume enterprise workflows scale geometrically with context length; documented cases show figures approaching seven figures monthly at scale. The intervention is straightforward in principle: implement an external memory architecture external vector stores, episodic memory, and compression pipelines to replace context-as-memory. The documented 60% cost reduction from proper memory engineering is not a theoretical target but an empirically demonstrated outcome.
RAG, by 2026, is table stakes rather than innovation. Enterprises still piloting RAG as a capability demonstration are behind the curve. The short-term competitive position is determined by the quality of what sits above RAG: the curation layer, the temporal memory layer, and the governance architecture. These are the differentiators; the retrieval mechanism is the commodity.
For enterprises using cloud-hosted models, the short-term posture is clear. The model is not the product the bridge layer is. Engineering investment should flow to perception connectors, curation pipelines, and memory governance, not to prompt engineering optimisation. Data residency must be contractually locked before the bridge is built, because every retrieval operation that passes private enterprise data to a cloud API is a potential compliance event.
For enterprises running locally hosted models Llama 4, Mistral Large, DeepSeek-V3.2 the short-term burden is higher. There are no native integrations, no managed safety layers, no built-in audit trails. The full RWCB stack is an internal engineering responsibility. The compensation is a fully private, auditable system that is not subject to vendor pricing changes or training data policy revisions. For regulated industries and sensitive data environments, this trade-off increasingly favours local deployment.
Medium Term: 2027–2028
The enterprise LLM reference architecture is transitioning from experimentation to strategic capital expenditure. Within two years, the dominant deployment pattern will be hybrid: cloud for burst capacity, heavy reasoning, and general knowledge; on-premise or private cloud for sensitive data, regulated workflows, and proprietary intelligence.
The RWCB architecture’s modularity is its most important medium-term strategic advantage. Its explicit interfaces between subsystems allow each layer to be independently pointed at cloud or local infrastructure without redesigning the whole stack. Enterprises that have built to the RWCB abstraction can execute the hybrid transition; those that have built point solutions against specific cloud providers face expensive re-architecture.
The medium term will also see the emergence of industry-specific RWCB implementations — standardised bridge configurations for healthcare, financial services, legal, and manufacturing verticals, with pre-built perception connectors for domain-specific data sources, domain-specific curation ontologies, and domain-specific compliance controls. These vertical implementations will significantly reduce the time and cost of bridge deployment for enterprises in well-defined sectors.
The most important medium-term development on the vendor landscape will be the consolidation of the orchestration layer. LangChain, LlamaIndex, CrewAI, and AutoGen are competing for this position; the winner or the open standard that emerges from their competition will become the dominant integration layer for enterprise AI deployments. MCP’s early traction as a connector protocol standard suggests that Anthropic has identified this layer as strategically significant.
Long Term: 2029 and Beyond
The long-term enterprise AI landscape is characterised by the full maturation of AI agency: systems that do not merely provide decision support but execute operational workflows autonomously, with the bridge providing the governance layer that makes autonomous execution safe.
The organisations that will win the long-term AI competition are not those that chose the best models models are becoming commodities, with frontier capability accessible from multiple providers at declining cost. The winners will be those that built the best bridges: proprietary, governed, temporally-aware context infrastructure that encodes their operational knowledge, their institutional history, and their strategic intent in a form that AI agents can act on reliably and safely.
The bridge layer is, in this framing, the new data moat. Where data moats in the first wave of digital transformation were defined by the accumulation of raw data, the AI-era data moat will be defined by the quality of the bridge that connects that data to AI reasoning.
Part VII: Non-Enterprise Implications: The Individual, Developer, and SME Lens
The Democratisation Opportunity
The most important fact about persistent memory for non-enterprise actors in 2026 is that the tooling to implement it has democratised far faster than most appreciate.
Open-source model capability has reached parity or near-parity with cloud frontier models on most practical non-enterprise tasks. DeepSeek-V3.2, Llama 4, Qwen 2.5, and Mistral Large are all available under permissive licences at zero marginal cost. The hardware barrier for meaningful local inference has fallen dramatically: an RTX 4090 (24GB VRAM) can run a 34B parameter model at full precision, delivering near-frontier quality for most knowledge work tasks at hardware costs below two thousand dollars.
Apple Silicon deserves particular attention. The M4 Ultra’s 192GB unified memory architecture runs a full 70B parameter model at FP16 precision with no degradation, consuming approximately 60W of power at a total system cost in the four to five thousand dollar range. For an individual practitioner or researcher, this is the single most cost-efficient path to frontier-quality local inference currently available.
The Goldman Sachs 2026 AI outlook identifies memory as the next frontier, noting that engineers’ focus will shift from building larger models to better memory. For non-enterprise actors, this means the productivity ceiling of local AI is no longer model quality it is memory architecture. The individual who implements even a basic RWCB-inspired memory layer on local hardware will have a qualitatively better AI assistant than one relying on unstructured cloud API calls.
Practical Memory for Individuals
For the individual power user or solo developer, a practical persistent memory implementation does not require the full RWCB stack. A meaningful approximation can be built from three components: a local vector database (Chroma or Qdrant, running locally with no external dependencies), an episodic memory store (a simple SQLite database capturing structured summaries of past interactions), and an orchestration layer (LangChain or LlamaIndex with a memory integration configured to retrieve from both stores at session start).
This configuration delivers session continuity, semantic recall of past interactions, and progressive personalisation the three properties that most distinguish a memory-aware assistant from a stateless one at effectively zero marginal cost once the hardware is in place.
The tooling for this stack is mature enough to deploy in an afternoon with competent Python skills. The intellectual challenge is not implementation but design: deciding what to remember, for how long, and in what form. These are the questions that the RWCB architecture addresses at enterprise scale; they apply equally, at smaller scale, to individual deployments.
SMEs and the Mid-Market Gap
Small and medium enterprises occupy an uncomfortable position in the current AI landscape. They have the operational complexity that makes persistent memory valuable longitudinal customer relationships, evolving internal processes, accumulated institutional knowledge but they lack the engineering capacity to implement the full RWCB stack internally.
The short-term solution for most SMEs will be to adopt a managed memory service (Mem0, Zep, or similar) integrated with a cloud LLM provider through a low-code orchestration layer. This delivers meaningful memory capability with minimal engineering overhead. The limitation is vendor dependency and the data governance uncertainty that comes with passing sensitive business context through multiple managed services.
The medium-term opportunity for the SME market is the emergence of vertical AI platforms packaged, industry-specific AI systems with memory architecture pre-configured for specific operational contexts. A platform designed for professional services firms, for example, might pre-integrate with common document management systems, CRM platforms, and billing systems, applying appropriate retention policies and access controls out of the box. This market is nascent in 2026 but will grow rapidly as the tooling matures.
Part VIII: The Native Integration Question : Will the Bridge Disappear?
This is the question that matters most for anyone making long-term architectural bets.
The evidence for native integration is substantial and growing. MemoryLLM demonstrates that persistent memory pools can be embedded within transformer layers with minimal overhead and maintained across nearly a million updates without degradation. Google’s Titans architecture shows that native long-term memory modules can outperform frontier models on complex long-context reasoning tasks while scaling to context windows exceeding two million tokens. OpenAI’s native memory is the first commercial demonstration that a frontier model provider can treat persistent memory as a platform feature rather than an external concern.
The trajectory of this evidence suggests that, within the next two to four years, frontier models will routinely include native long-term memory as a standard architectural component. Session continuity, personalisation, and high-frequency contextual adaptation will be handled natively, without requiring external infrastructure.
Does this render the bridge obsolete?
The answer is no, and the reasons are structural rather than transitional.
Five arguments support the permanence of the external bridge regardless of how sophisticated native memory becomes.
The first is the private data problem. The world changes faster than training cycles, and private enterprise data proprietary contracts, internal policies, customer records, operational state will never reside in public training data. No amount of native memory sophistication addresses information the model was never exposed to.
The second is the provenance and accountability problem. A model cannot audit its own memory. Evidence chains, access logs, source attribution, and conflict resolution must live in an external layer that is independently verifiable. For any regulated or auditable decision, the model’s own memory is insufficient as an evidentiary basis.
The third is the security enforcement problem. Prompt injection, data poisoning, and tool misuse risks grow as models become more capable of acting in the world. Safety must be enforced at the boundary between model and environment a boundary that an external bridge defines and controls. Internalising memory internalises the attack surface.
The fourth is the regulatory compliance problem. GDPR deletion rights, data residency requirements, retention schedules, and consent management cannot be implemented inside model weights. They require external, auditable data systems with explicit lifecycle management. No native memory architecture can satisfy these requirements.
The fifth is the ground truth problem. An organisation’s ground truth its policies, its customer records, its operational state is contextual, private, and subject to rapid change. No general-purpose model, however sophisticated its native memory, can substitute for a purpose-built, governed knowledge store that the organisation controls.
The emerging consensus from the research literature resolves this not as a binary choice but as a complementary architecture: native memory handles session continuity, personalisation, and high-frequency context; external bridges handle authoritative, auditable, policy-governed enterprise knowledge. This is exactly the architecture the RWCB specification anticipates in its distinction between hot, warm, and cold storage tiers.
The hybrid is not a compromise. It is the correct answer.
Part IX: Assessing the Body of Knowledge AI bridge
What the Corpus Gets Right
The body of knowledge represented across the documents reviewed for this analysis is, taken together, architecturally sound and strategically sophisticated. Its central thesis that the bridge layer is now the competitive differentiator in enterprise AI, not the model itself is correct, and it will prove more correct with each passing year as model capability commoditises.
The RWCB specification’s modular architecture, its explicit separation of concerns, its treatment of human oversight as a first-class design option, and its five-tier enterprise maturity framework are all conceptually strong and practically grounded. The multi-agent memory taxonomy distinguishing working memory, episodic memory, semantic memory, procedural memory, consensus memory, and persona memory provides the most operationally useful vocabulary for this domain currently available in the non-academic literature.
The hardware analysis in the non-enterprise section is notably accurate and practically useful. The Apple Silicon recommendation, in particular, reflects a correct reading of the current hardware landscape that many practitioners miss by focusing on GPU-centric inference.
Where the Corpus Falls Short
The body of knowledge has three notable gaps.
The evaluation and measurement framework is underdeveloped: The corpus identifies that bridging is valuable but provides limited guidance on how to measure whether a given bridge implementation is performing well. The emerging benchmarks (TIME, ChronoQA, TimeShift) are referenced but not integrated into a practical evaluation protocol.
The forgetting and retention policy model is absent: as noted in the architectural critique. The corpus describes what the temporal memory layer should do but does not specify how it should manage the lifecycle of stored information. This is the most significant practical gap in an otherwise robust specification.
The transition economics : the cost and complexity of moving from current-state (typically basic RAG or context-window-as-memory) to RWCB target-state are not addressed. Enterprises need not only the target architecture but a realistic assessment of the migration path, including the intermediate stages and the ROI inflection points.
The Broader Research Landscape
Situated within the broader research landscape, the RWCB framework is well-aligned with the direction of academic and commercial work. The Memory Bear research, the Titans architecture, MemoryLLM, and the Temporal RAG developments all converge on the same fundamental insight: memory is infrastructure, not a feature, and it requires dedicated engineering rather than ad hoc context management.
The field’s convergence on this view is accelerating. The 2026 statistic that 67% of enterprise AI deployments planned dedicated memory systems compared to 12% in 2025 is the clearest indicator that the industry is reaching the same conclusion the RWCB specification articulates. The question is not whether persistent memory architecture matters, but who will build it well, who will govern it appropriately, and who will make the architectural bets that determine competitive advantage over the next three to five years.
Conclusion
The memory problem is the grounding problem. The grounding problem is the central unsolved challenge in applied AI. And the central unsolved challenge in applied AI is now the primary determinant of competitive advantage in enterprise AI deployment.
This is not an exaggeration. The organisations that will lead in AI-augmented operations over the next five years are not those that secured access to the most capable models model access is becoming a commodity. They are those that built the best bridges: the most governed, most temporally aware, most architecturally mature context infrastructure that connects static model intelligence to the living, changing world of their operations.
The Real-World Context Bridge, as a framework and as an architecture, represents a robust publicly documented approach to this problem currently available. Its strengths are significant: modular design, explicit separation of concerns, governance-first orientation, and alignment with both academic research directions and commercial development trajectories. Its gaps the missing forgetting model, the absent causal chain modelling, the underdeveloped evaluation framework are addressable and the research to address them exists.
The native integration question resolves to a complementary architecture: native memory for continuity and personalisation, external bridges for governance, provenance, and enterprise truth. This is not a transitional state pending better models. It is the permanent architecture of enterprise AI, for the same reasons that no organisation would allow its financial records to reside only in an employee’s memory, however excellent that memory might be.
For the individual practitioner, the developer, the researcher, and the SME: the tools to implement meaningful persistent memory are available today, at low or zero cost, on hardware that fits under a desk. The barrier is not access but understanding and the RWCB framework provides the conceptual vocabulary to move from ad hoc prompt engineering to deliberate memory architecture.
The field is converging on this understanding. The organisations and individuals who arrive first will have the advantage.
Next Steps

For Enterprise Architects and Engineering Leaders
Immediate (within 90 days): Conduct a maturity assessment against the five-stage RWCB adoption framework. Identify your current position , most organisations in 2026 sit at Stage 1 (basic RAG) or Stage 2 (tool use). Identify the gap to Stage 3 (governance) and build the roadmap from there. Stop treating context window expansion as a memory strategy; quantify the cost implications and present them to leadership as a financial architecture decision.
Short term (3–12 months): Implement the perception and curation subsystems for your highest-value use case the knowledge worker assistant is the recommended starting point for most organisations. Deploy external vector stores and episodic memory to replace context-as-memory in high-volume workflows. Establish a cross-functional RWCB governance board representing AI design, engineering, data science, security, compliance, and business operations.
Medium term (1–3 years): Develop the temporal memory and alignment subsystems. Incorporate Temporal RAG (E2RAG, DyG-RAG patterns) into the retrieval pipeline. Adopt MCP as the standard connector protocol for the perception layer. Build toward the hybrid deployment architecture cloud for burst and general reasoning, on-premise for sensitive and regulated workloads.
Long term (3+ years): Publish your RWCB implementation as an enterprise standard. Build proprietary vertical implementations for your specific domain. Monitor the native memory trajectory in frontier models and adjust the hot-tier architecture accordingly as native memory matures.
For Developers and Individual Practitioners
Start today: Deploy a local vector database (Chroma or Qdrant) and integrate it with your preferred LLM via LangChain or LlamaIndex. Add a simple SQLite episodic memory store. Configure session-start retrieval from both. This delivers 80% of the value of persistent memory in a weekend implementation.
Build deliberately: Design your memory schema before you implement retrieval. Decide what categories of information you want to persist (domain knowledge, past decisions, user preferences, project context), in what form, and for how long. The RWCB taxonomy working, episodic, semantic, procedural provides the vocabulary.
Invest in hardware if volume justifies it: For practitioners with regular, high-volume AI workflows, local inference with Apple Silicon (M4 Ultra or equivalent) combined with a local memory stack delivers the best combination of privacy, capability, and cost over a two-to-three-year horizon.
For Researchers
Priority research directions: Develop a formal forgetting and retention policy model for temporal memory systems, informed by MemoryLLM’s decay mechanisms and Memory Bear’s base-level activation formulas. Extend the RWCB specification with causal chain modelling, drawing on E2RAG and DyG-RAG paradigms. Establish a standard RWCB evaluation suite using TIME, ChronoQA, and TimeShift benchmarks.
Publication priority: The multi-agent consensus memory problem the structural gap between single-agent and multi-agent memory architectures is under-researched relative to its practical importance. The field needs formal treatments of consensus protocols for AI agent teams that go beyond the heuristic implementations currently in production.
Collaboration priority: The convergence between cognitive science (ACT-R, Ebbinghaus) and AI memory architecture (Memory Bear, MemoryLLM) is producing the field’s most significant advances. Cross-disciplinary collaboration between cognitive scientists and AI engineers should be a priority for research institutions positioning themselves at this frontier.
This article synthesises original analysis with a review of the research literature current to February 2026, including arXiv:2512.20651 (Memory Bear), Google Titans (December 2025), arXiv:2505.17670 (CoMEM), arXiv:2504.15965 (Survey on Memory Mechanisms), arXiv:2510.09720 (Preference-Aware Memory Update), MemoryLLM (Wang et al., 2024), and the E2RAG and DyG-RAG temporal reasoning literature. Industry data includes Goldman Sachs AI Outlook 2026 and enterprise adoption statistics from production deployment surveys.




{kind=link}
{kind=link}
{kind=link}
{kind=link}