
A field guide for founders, solo builders, and enterprise teams trying to move fast with AI without losing control of quality, security, or governance
Preamble, the moment the illusion broke
The author wants the non-programmer, a solo programmer, enterprise nonprogrammer and enterprise programmer to continue use vibe coding but do it safely and derisked. The AI vibe coding genie is out of the bottle. In early 2025, Andrej Karpathy gave a name to something many people had already started doing in fragments: vibe coding. You tell the AI what you want, accept what it gives you, and move forward without dwelling too much on the implementation. It sounded liberating because, in some ways, it was. Within months, the phrase spread everywhere. By 2026, AI-assisted coding had gone from novelty to default behavior across startups, internal product teams, and large engineering organizations. Non-technical founders were shipping prototypes over a weekend. Product managers were building working demos without waiting for engineering bandwidth. YC startups were openly discussing majority-AI codebases. The jump from idea to interface had become shockingly small.
But the same compression that made vibe coding exciting also made it dangerous. It did not just compress the distance between idea and software. It compressed the distance between working and unsafe. A screen that loaded, a login flow that appeared to function, a database that returned records, all of it could create the impression that the product was farther along than it really was. Underneath the polished surface, the system might still be missing authorization checks, environment separation, auditability, accessibility, resilience, or even basic secret handling. That gap is where many of the real failures of the past year have lived.
Then came the harder evidence. Open databases. Client-side authentication. Hardcoded secrets in public repositories. Hallucinated dependencies that attackers could register and weaponize. Production apps built quickly and trusted too early. The tone of the conversation changed because the consequences became real: CVEs tied to AI-generated code, public breaches, exposed user messages, leaked tokens, and systems that looked functional until someone checked the wrong layer. The illusion broke when people realized that software can be visually convincing and operationally reckless at the same time.
This is not an argument against vibe coding. It is an argument against using it carelessly. The technology is powerful. The acceleration is real. The economic and creative upside is obvious. But the discipline required to use it well has been badly misunderstood. The real reckoning is not whether vibe coding works. It does. The real question is for whom, under what conditions, with which controls, and at what stage of the product lifecycle.
A separate companion article documents the current known problems of vibe coding and their mitigations (see references: Vibe coding). Because the landscape changes monthly,the user need to update regularly. This article focuses instead on the more stable patterns: what vibe coding actually is, how different personas should use it, where it breaks down, and what responsible practice looks like in 2026.
As usual references: Vibe coding
| Document name | Short summary |
| Known_Vibe_Coding_Issues_Updated | A structured reference list of common vibe coding risks, consequences, mitigations, and practical safeguards.it changes regularly |
| Lightweight Vision, PRD, and SRS Template Pack | A combined lightweight template pack for non programmers: solo and enterprise users covering vision, PRD, and SRS documents. |
| SRS Template Pack | Solo User and Enterprise | A portfolio-ready software requirements specification pack with solo and enterprise templates, including traceability and operational controls. |
| Vision Document Template Pack | A professional template pack for solo and enterprise vision documents with editable placeholders and optional appendices. |
| Product Requirements Document Template Pack | A structured PRD template pack for solo builders and enterprise teams, with sections for scope, features, risks, AI use, and governance. |
| Guide to the Two-AI Workflow | How to use a planning AI and a building AI without losing speed, clarity, or control. The Two-AI Workflow is one of the most useful ways to make vibe coding safer without making it slow. The basic idea is simple. You use one AI to think. You use another AI to build. |
What vibe coding actually is
At its core, vibe coding is prompt-driven software development. You describe the system in natural language, the AI generates code and configuration, you run it, inspect the behavior, paste back errors, and keep iterating. The human role shifts away from line-by-line authorship and toward direction, selection, and acceptance. That shift is what makes the workflow feel fast. It is also what makes it risky, because the human often evaluates output by surface behavior instead of implementation quality.
That does not mean all AI coding is the same. One of the biggest sources of confusion in the market is the tendency to put every AI-enabled development workflow under one label. In practice, there are at least four distinct modes.
AI-assisted coding is the broadest category. A developer uses AI as a helper inside a normal engineering workflow. The developer still owns the architecture, reads the code, reviews the diff, and decides what ships. AI suggestions speed up work, but they do not replace engineering judgment. This is the lowest-risk mode because the human remains firmly inside the implementation loop.
Pure vibe coding is more radical. The user describes what they want and accepts what the model produces largely on the basis of whether it appears to work. The code itself becomes secondary. This is the mode Karpathy’s phrasing captured so well, and it is the mode that produces both the strongest feeling of empowerment and the highest chance of false confidence.
Full-stack AI app builders such as Lovable, Bolt.new, Replit Agent, and Base44 take that workflow even further. They do not just suggest functions or files. They generate entire applications, often including frontend, backend, database schema, authentication, and deployment setup. These tools can be extraordinary for speed, especially for non-programmers, but they also create the lowest visibility into what is actually happening across the stack. That is why they carry the highest hidden risk when used beyond prototype level.
AI code editors such as Cursor, Windsurf, Claude Code, and GitHub Copilot are different. They are closer to power tools for programmers. They accelerate people who already know how to reason about code, architecture, environments, dependencies, and failure modes. They can still create serious problems, especially if users overtrust them, but they generally sit inside a more conventional engineering loop with more human visibility and more opportunities for intervention.
This distinction matters because the central danger of vibe coding is not speed. It is false completeness. The software looks finished long before it is secure, maintainable, accessible, scalable, or governable. A working interface is easy to mistake for a working system. A generated login screen is easy to mistake for a trustworthy authentication model. A deployed app is easy to mistake for an operational product. In 2026, that misunderstanding is still the root cause of many failures.
The four personas of vibe coding
1. The non-programmer solo builder
This persona has gained the most from vibe coding, and is also the easiest to mislead. A non-programmer can now create prototypes, internal tools, landing-page workflows, lightweight SaaS experiments, and data-backed demos that would previously have required hired engineering time. For idea validation, this is a genuine breakthrough. It lets founders and operators test demand earlier and learn faster.
The blind spots are obvious once you know where to look. The non-programmer solo builder usually has limited intuition for security boundaries, weak visibility into generated code, little instinct for missing non-functional requirements, and no natural feel for where a demo stops and an MVP begins. They are particularly vulnerable to hidden flaws in secret handling, access control, environment setup, logging, backup, preview exposure, and data retention. Their most common failure mode is shipping something that appears polished but is operationally under-specified.
This is also the persona most likely to underestimate hallucinations. A generated package name, auth flow, deployment step, or database policy may look plausible enough to trust. Without technical review, hallucinated dependencies, weak authentication, missing RLS, or incorrect infrastructure assumptions can pass through untouched. Accessibility debt also hides easily here, because a UI that looks modern to the builder may still fail keyboard navigation, semantic structure, focus visibility, or contrast requirements.
Responsible practice for this persona means staying agile without pretending to be an engineer. Write a lightweight PRD. Decide early whether the target is a demo or an MVP. Use managed hosting carefully. Keep real user data out of the system until someone qualified has reviewed the setup. Treat every generated output as untrusted by default. Use a second AI as a reviewer. Export everything to Git from the start. Use vibe coding aggressively for concept validation, UI exploration, and workflow prototyping, but avoid using it alone for systems involving sensitive data, payments, regulated workflows, or long-term maintainability obligations.
2. The programmer solo builder
The solo programmer gains something different from vibe coding: leverage. Boilerplate moves faster. Scaffolding is cheaper. Repetitive transformations are easier. Architecture can be explored quickly. Side projects that would once have been delayed for weeks can now reach usable form much faster. Used well, this is one of the best uses of AI in software work.
The blind spots here are subtler. The programmer knows enough to trust themselves, and that can become a trap. They may overtrust the model on implementation details they would never have delegated in the past. They may let architectural drift creep in across sessions. They may accept inconsistent patterns because the code basically works. They may accumulate technical debt faster than they notice because AI removes the pain that once slowed down careless expansion. Their failures tend to come less from total ignorance and more from a mismatch between perceived control and actual review depth.
This persona also runs into hallucinations differently. A strong developer can catch a lot, but not everything, especially in long sessions or fast-moving projects. Hallucinated APIs, invented config flags, fragile library assumptions, or quietly insecure defaults can slip through because the builder’s attention is distributed across many concerns at once. Missing NFRs are another common gap. Performance, observability, recovery, rate limiting, backup, accessibility, and compliance can all be postponed because feature delivery feels so fast.
Responsible practice for the programmer solo builder means using AI where speed is useful and keeping your skepticism where correctness matters. Use vibe coding for scaffolding, CRUD paths, UI assembly, refactors, and low-risk integration glue. Avoid relying on it blindly for security-critical code, cryptography, payment logic, compliance-sensitive flows, and anything requiring deterministic correctness. Maintain strict version control. Use static analysis, dependency scanning, tests, and environment discipline. Stay agile by shrinking tasks, not by lowering standards.
3. The enterprise non-programmer, or citizen developer
This persona is the one most organizations still underestimate. Enterprise non-programmers can now build internal tools, automate reporting flows, prototype process improvements, and reduce pressure on engineering backlogs. There is real business value here, especially in departments that have historically waited months for simple workflow support.
But the failure modes are severe. This is where shadow AI development becomes a governance issue. A business user can create an apparently helpful internal tool that touches real customer data, uses unapproved services, bypasses review, has no logging, no testing, no traceability, and no support model. The user often does not think of themselves as shipping software, but that is exactly what they are doing. The result is shadow IT, shadow AI, data leakage, compliance risk, and unmonitored production-like behavior appearing outside normal controls.
Their blind spots usually include security, auditability, retention rules, access control, environment management, and the fact that enterprise software is judged not just by utility but by governance. They may not understand why regulated data, audit trails, role boundaries, and infrastructure ownership matter so much. They may also underestimate platform lock-in, especially when an AI builder makes deployment feel effortless.
Responsible practice here requires organizational support, not just user caution. Use only approved platforms. Require a PRD for prototypes and a PRD plus SRS for anything beyond them. Restrict access to production systems and regulated data. Force review gates. Require traceability from requirement to implementation and from implementation to test. Keep citizen development inside governed channels, with safe templates, approved connectors, and explicit escalation paths. Enterprise non-programmers should absolutely use vibe coding for low-risk internal workflows and prototypes. They should not use it alone for regulated, customer-facing, or business-critical systems.
4. The enterprise programmer or engineering team
This is the persona most likely to talk confidently about vibe coding and also the one most likely to experience its organizational downsides at scale. Engineering teams gain real speed from AI code editors and selective generation. Boilerplate falls away. Implementation starts faster. Internal platform work becomes less tedious. Patterns can be replicated quickly.
The blind spots here are systemic. Technical debt can accumulate faster than teams can review it. Inconsistent patterns spread across repositories. Review fatigue sets in because generated diffs are large and frequent. Traceability suffers because commit history stops reflecting human reasoning. Configuration drift becomes easier to introduce. Teams can find themselves surrounded by code that technically belongs to them but that nobody deeply understands.
Their failure modes include overproduction of mediocre code, weakened architectural coherence, insufficient test depth, NFR drift, hallucinated dependencies, and governance breakdown when generated changes move faster than existing CI/CD and review culture can absorb. In larger organizations, the challenge is not whether engineers can use AI. It is whether the surrounding engineering system can still maintain evidence, ownership, and control.
Responsible practice for this persona means integrating AI into disciplined engineering rather than letting it become an end-run around it. Keep PRDs and SRSs current. Require prompt-to-commit traceability for meaningful generated work. Run static analysis, dependency scanning, security checks, and proper CI/CD on all generated code. Maintain environment separation. Require senior signoff where risk warrants it. Use vibe coding heavily inside low-risk and medium-risk work, but do not let it replace deliberate design, review, or governance in safety-critical, regulated, or deterministically correct systems.
Requirements matter more, not less
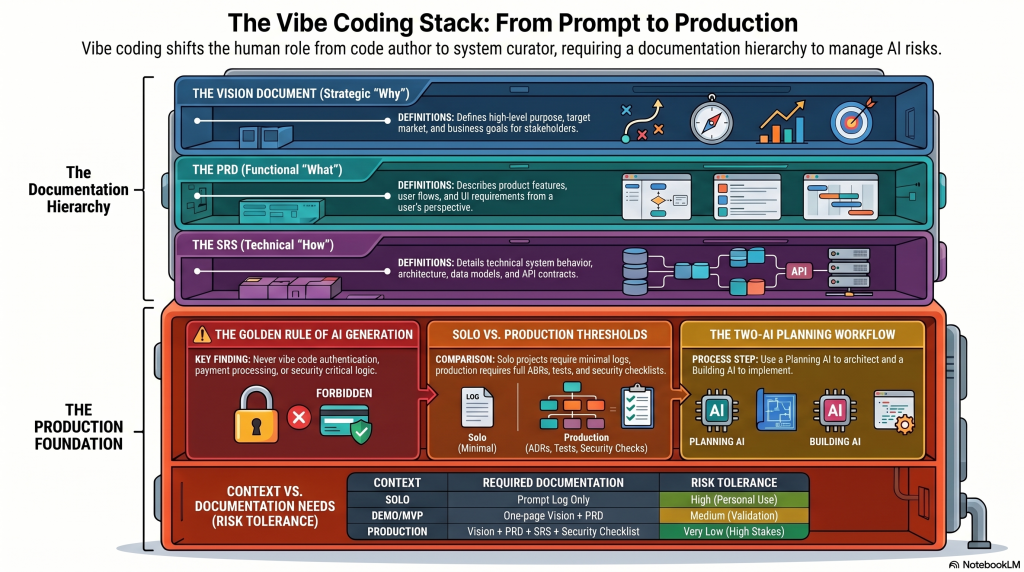
One of the most persistent myths about vibe coding is that it reduces the need for requirements. In reality, it increases it. When a human engineer is writing code manually, some ambiguity gets resolved through experience, context, and explicit design conversation. When an AI generates the implementation, ambiguity gets resolved statistically. The model fills in the gaps with probable answers, not necessarily correct ones. If the requirement is vague, the generated system will still be specific. That specificity is where the risk comes from.
A PRD, or Product Requirements Document, defines intent. It tells the AI, and the humans around it, what the product is for and what the current release is supposed to achieve.
In a good vibe-coding workflow, the PRD should include: problem statement; target users; workflows or user journeys; features and priorities; constraints; supported platforms or chosen stack; business rules; success measures; release intent, meaning demo, MVP, or production.
An SRS, or Software Requirements Specification, defines obligations. It is the technical and operational counterpart to the PRD.
In a responsible workflow, an SRS should include: functional requirements; non-functional requirements; security requirements; accessibility requirements; data requirements; integration requirements; environment requirements; logging, monitoring, backup, and recovery expectations; test and acceptance criteria; constraints and assumptions.
The PRD and SRS are not competing documents. They do different jobs. The PRD says what and why. The SRS says how well, under what conditions, and with which obligations. For a solo builder doing a quick prototype, a lightweight PRD may be enough. For an MVP, especially one with real users or real data, a PRD plus an SRS-lite is usually the safer line. For enterprise work, or anything regulated, the SRS should not be optional.
Demo versus MVP versus production
This is the single most important distinction in vibe coding, and one of the most frequently ignored.
A demo is there to prove the idea. It can use mocked data, simplified flows, limited auth, and partial error handling. It is allowed to be disposable. It should still avoid obvious negligence, but it does not need the full operational scaffolding of a real product. This is where vibe coding is strongest. It can make exploration dramatically cheaper.
An MVP is not just a polished demo. It is the first version that touches real users, real data, and real expectations. That changes the standard immediately. Now you need real authentication, secrets management, environment separation, database security, rate limiting, logging, backup, accessible user journeys, and actual support for failure states. The move from demo to MVP is where many vibe-coded projects fail because the surface of the app changes less than the underlying obligation. Teams are tempted to reuse what already works, but the risk model has changed completely.
A production release raises the bar again. At this point, the system needs staged environments, audit trails, operational ownership, monitoring, alerting, controlled release processes, rollback paths, and, where relevant, compliance evidence and threat modeling. AI can still help here, but it must sit inside a governed SDLC. It cannot substitute for one.
The practical rule is simple. If the audience is controlled and the data is fake, you are still in demo territory. If real users can sign in, upload, pay, or trust the output, you are in MVP territory at minimum. If the business depends on the system staying available, secure, and explainable, you are in production territory whether you admit it or not. Many of the public failures of the past year came from pretending those categories were interchangeable. They are not.
The AI-to-AI workflow, AI as architect and AI as builder
One of the most useful patterns to emerge from serious vibe-coding practice is the two-AI workflow.
The first AI is the planning AI. This can be Claude, ChatGPT, Gemini, or another strong general reasoning model. Its job is not primarily to generate the product directly. Its job is to hold the context that keeps the build honest. It should receive the PRD, the SRS where applicable, the stack choices, budget constraints, hosting choices, security expectations, target release class, and major risks. It should then produce an implementation guide, reason about trade-offs, identify hidden assumptions, propose tests, and challenge the plan before code is generated.
The second AI is the building AI. This is the vibe-coding platform or AI code editor actually generating the implementation. Lovable, Cursor, Replit, Windsurf, Bolt.new, and similar tools sit here. Their job is execution: generate code, implement features, propose diffs, scaffold structure, and respond to defects or change requests.
Used properly, the planning AI becomes a validator and stabilizer for the building AI. It can validate the vibe-coded output against the PRD and SRS, detect likely hallucinations or invented dependencies, catch architectural drift between sessions, enforce stack and hosting constraints, maintain traceability from requirement to implementation, and keep the workflow lean by surfacing mistakes early rather than after deployment.
In practice, the workflow is straightforward. The planning AI produces an implementation guide. The building AI generates code or configuration. You compare the output to the guide. If there is a divergence, you ask the planning AI whether the change is sensible or risky. You repeat that loop at milestone points, especially before major feature merges, before deployment, and before any transition from prototype to MVP or MVP to production.
This approach works differently by persona. For a non-programmer, it provides a way to reason about correctness without needing to inspect every line of code. For a solo programmer, it acts as a design backstop and a hallucination detector. For enterprise non-programmers, it gives governance teams a better way to standardize building behavior. For enterprise engineers, it provides a way to connect generated implementation back to documented intent. In all cases, it helps agility because it reduces expensive rework. It is faster to detect drift early than to unwind it later.
Should everyone use two AIs this way? Not always. For trivial experiments, it can be overhead. But once the system has real users, real data, real complexity, or real organizational stakes, the two-AI pattern is one of the cleanest ways to stay fast without giving up discipline.
Security, accessibility, and the hidden layer most teams still miss
Vibe coding tends to optimize for visible function. It does not naturally optimize for what mature delivery teams would call the hidden layer: security, accessibility, observability, resilience, maintainability, governance, and ownership. Those things do not disappear because AI is writing code. If anything, they become more important because so much of the implementation is generated at speed.
Security remains the clearest area of recurring failure. Hardcoded secrets, missing authorization checks, client-side authentication logic, incomplete database controls, missing security headers, weak input validation, unsafe dependency choices, and preview environments exposed too early are all recurring patterns in AI-generated systems. The lesson is not that AI cannot write secure code. It can. The lesson is that secure code rarely appears by accident. Security has to be explicit, reviewed, and tested.
Accessibility behaves differently but is just as important. Many generated interfaces look finished while failing keyboard navigation, semantic structure, focus handling, readable contrast, or accessible authentication flows. Because these defects often do not affect a developer’s own test path, they can survive for a long time. In public and enterprise systems alike, that is a usability problem, a legal problem, and a quality problem. If accessibility is not named in the PRD, required in the SRS, and checked before release, it will usually be under-built.
Governance is not the opposite of agility
There is a lazy framing that still shows up in some conversations: either you move fast with vibe coding or you slow everything down with process. That is the wrong model. Good governance is not there to remove speed. It is there to stop false speed from turning into expensive instability.
For individuals, governance looks like simple clarity: write the PRD, define the release class, protect secrets, use version control, keep real data out until you are ready, and review what matters. For enterprises, governance means approved use cases, platform boundaries, PRD and SRS requirements, review gates, CI/CD enforcement, secret management, auditability, and visibility into where AI-generated code is appearing. None of this prevents useful acceleration. It just prevents acceleration from becoming invisible debt.
The same principle applies to shadow AI development. You do not stop it by pretending it will not happen. You reduce it by giving people safe channels, better defaults, clear review paths, and tools that make responsible behavior easier than irresponsible behavior. The enterprise that forbids everything usually gets hidden use. The enterprise that governs intelligently gets usable acceleration.
Conclusion, the discipline the future still requires
Vibe coding is powerful, but it is not magic. It does not remove the need for requirements. It does not remove the need for judgment. It does not remove the need for governance. If anything, it increases the value of all three.
That is the real reckoning. The faster generation becomes, the more important explicit constraints become. The easier it is to get a working interface, the more important it becomes to distinguish visible progress from actual readiness. The more code AI can produce, the more important it becomes to preserve evidence, ownership, and review.
The best builders in 2026 are not the ones who surrender most completely to the vibes. They are the ones who know when speed helps, when caution is mandatory, and when structure is what keeps momentum from collapsing. They combine speed with review, and generation with evidence. They use PRDs and SRSs not as paperwork, but as anchors. They use AI as an accelerator inside a disciplined process, not as an excuse to abandon one.
That is true for the founder building alone, for the programmer trying to move faster without degrading quality, for the citizen developer inside a large organization, and for the enterprise engineering team trying to absorb AI without losing control of the system it is meant to improve. Vibe coding can absolutely help all of them. But it helps most when it is treated as a powerful method inside software discipline, not as a replacement for software discipline itself.
Addendum to The Vibe Coding Reckoning: 2026 Edition
Appendix expansion on architecture, testing, configuration, change, version control, and a document-use map by persona and release stage: Appendices
These appendices extend The Vibe Coding Reckoning: 2026 Edition with practical guidance for building more safely and systematically with AI. They cover testing, configuration management, change control, version control, technical architecture, including data, AI, interfaces, and broader enterprise architecture, and explain when UX, UI, and user journey design should shape the work. They also include a document map showing which supporting documents to use, for whom, at what stage, and whether each is optional, recommended, or expected across demo, MVP, and production contexts.


{kind=link}
{kind=link}
{kind=link}
{kind=link}