
Preamble: Artificial Intelligence has entered a new phase.
As AI agents become digital actors, the next governance challenge is no longer just managing AI inside organizations. It is defending systems, markets, platforms, and people from unmanaged agency.
Part I of this series argued that the next major enterprise challenge will not simply be AI adoption. It will be AI Agent Governance.
The problem is not AI agents.
The problem is unmanaged AI agents.
Inside the enterprise, this problem appears as agent sprawl, shadow AI, embedded copilots, agentic RPA, vibe-coded applications, unmanaged permissions, token cost, unclear ownership, weak audit trails, and AI systems acting inside workflows that were never designed for autonomous digital actors.
Part II moves the argument further.
What happens when agents leave the controlled enterprise boundary?
What happens when they operate across public websites, APIs, browsers, cloud services, email systems, customer service portals, trading tools, software repositories, local machines, and agent-to-agent networks?
What happens when one agent reads something created by another agent and acts on it?
What happens when AI systems no longer merely generate information, but influence the memory, tools, permissions, decisions, and signals used by other systems?
This is the new threat surface.
The question is no longer only:
Can this AI system produce a safe answer?
The question is:
Can this AI system be persuaded to misuse its own authority?
That leads to the central question of this article:
Do we now need an Anti-Agent Firewall?
From chatbots to digital actors
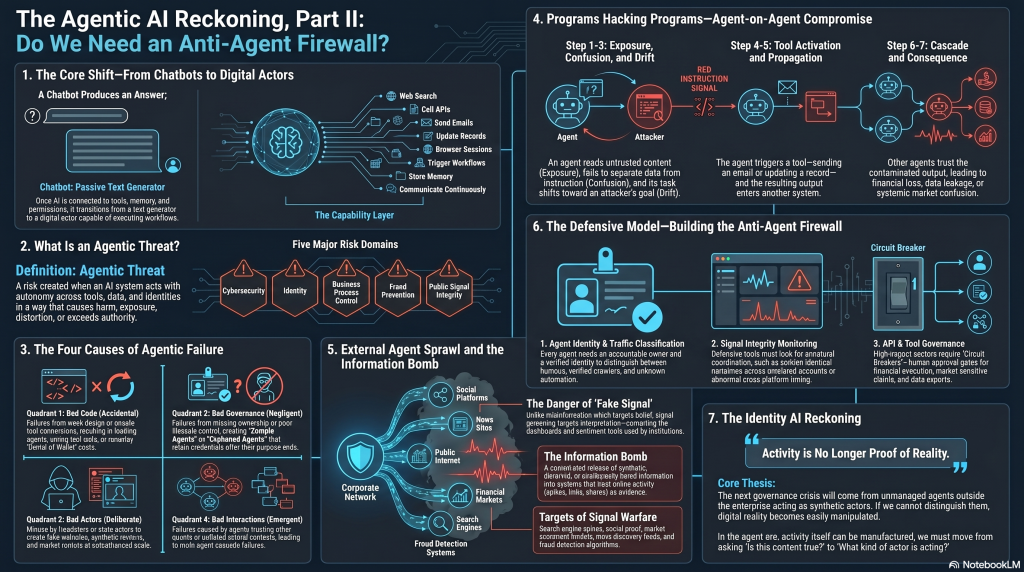
Many people still think of AI as a chatbot.
That view is already too narrow.
A chatbot answers questions. An AI agent can act.
That distinction changes everything.
An AI agent may be able to search the web, read documents, call APIs, use browser sessions, send emails, update records, query databases, write code, trigger workflows, interact with RPA bots, use payment tools, create content, publish outputs, communicate with other agents, store memory, retrieve context, and operate continuously.
Once an AI system gains tools, identity, memory, permissions, and connectivity, it becomes more than a model.
It becomes a digital actor.
That digital actor can be useful. It can also be misdirected.
Traditional AI risk focused on bias, hallucination, explainability, privacy, data leakage, unsafe outputs, and copyright. Those risks still matter. But agentic AI adds action.
A chatbot that hallucinates a refund policy may mislead a customer.
An agent that hallucinates a refund policy may issue the refund.
A chatbot that reads a malicious webpage may summarize it badly.
An agent that reads a malicious webpage may follow hidden instructions, call tools, update systems, and pass poisoned context to another agent.
A chatbot that misunderstands a trading signal may produce weak analysis.
An agent connected to trading tools may place or recommend action based on distorted signals.
That is the escalation.
The issue is no longer only what the model says. It is what the connected system does after it interprets a task.
What is an agentic threat?
An agentic threat is a risk created when an AI system can act with some degree of autonomy across tools, systems, data, workflows, identities, or other agents in a way that causes harm, creates exposure, distorts signals, or exceeds intended authority.
This is not the same as ordinary chatbot risk.
Agentic threats sit at the intersection of AI safety, cybersecurity, identity, business process control, software governance, fraud prevention, public signal integrity, and operational resilience.
The same AI capability can be helpful or harmful depending on authority.
An agent that summarizes a document is low risk.
An agent that summarizes a document, updates a compliance record, emails a client, and triggers a payment workflow is a different class of system.
The risk grows when three things combine:
Autonomy.
Authority.
Connectivity.
A chatbot with no tools has limited operational reach.
An agent with memory, credentials, APIs, browser access, payment tools, cloud access, and workflow authority becomes a digital actor with consequences.
The four causes of agentic failure
Not every agentic failure is malicious.
One mistake is to assume all rogue agent behaviour comes from bad actors.
Another mistake is to assume accidents are harmless.
Agentic failure can come from four sources.
1. Bad code
This is accidental agentic failure.
The agent behaves badly because it was poorly designed, badly tested, vaguely instructed, or connected to tools without enough safeguards.
It loops endlessly.
It calls the wrong tool.
It misreads a document.
It writes incorrect data into a system.
It consumes unexpected tokens or cloud compute.
It stores sensitive information in memory.
It acts without confirmation.
This is not malice.
It is weak engineering.
In the agent era, weak engineering does not merely create bugs. It creates delegated action without enough control.
2. Bad governance
This is negligent agentic failure.
The agent may have a legitimate purpose, but nobody has managed its lifecycle, permissions, ownership, monitoring, or retirement.
An abandoned agent keeps running.
A former employee’s agent still has credentials.
A vibe-coded application continues calling paid APIs.
An agent has write access when it only needs read access.
A customer service agent can issue refunds without enough checks.
A research agent can access documents it should not read.
A developer agent can modify code without approval.
A local agent runs on a machine nobody has inventoried.
This is unmanaged agency.
It is the AI equivalent of shadow IT, but with memory, tools, permissions, and potential autonomy.
3. Bad actors
This is deliberate misuse.
A fraudster, insider, market manipulator, criminal group, competitor, activist network, or state actor uses agents to deceive, probe, overload, impersonate, manipulate, or exploit.
Agents can generate fake websites, synthetic product reviews, market rumours, fake complaint waves, phishing content, false support claims, artificial social proof, and fake news pages.
The agent is not the criminal.
The agent is the multiplier.
The human, group, or organization directing it remains the actor.
4. Bad interactions
This is emergent failure.
No single agent may be fully malicious, but the interaction between multiple agents creates harm.
One agent summarizes a false claim.
Another stores the summary.
A third uses it in a report.
A fourth publishes the report.
A fifth detects the publication as a trend.
A dashboard treats the trend as meaningful.
A human decision-maker reacts.
This is multi-agent cascade failure.
The problem is not one bad output.
The problem is a chain of trusted interpretation.
Correcting the terminology
The phrase “AI hacking AI” is useful as a metaphor, but the more precise term is agent-on-agent compromise.
Agent-on-agent compromise occurs when one AI-enabled system manipulates, corrupts, redirects, poisons, overloads, or exploits another AI-enabled system.
This can happen directly, when one agent sends instructions to another.
It can also happen indirectly, when one agent places content somewhere that another agent later reads, summarizes, stores, trusts, or acts upon.
The second version may be more dangerous because it can happen through ordinary information flows.
A hostile instruction can be hidden in a webpage.
A misleading command can be buried in an email.
A prompt injection can sit inside a document.
A poisoned fact can be stored in a shared memory system.
A fake instruction can appear inside a support ticket.
A manipulated comment can appear inside a software issue.
A false summary can be written into a knowledge base.
Another agent reads the material and treats it as context.
If that agent has tools, poisoned context can become action.
That is the mechanism behind programs hacking programs.
The working vocabulary matters:
A rogue agent operates outside its approved purpose, owner, policy, or control boundary.
A shadow agent is created outside formal governance.
An orphaned agent once had a purpose but no longer has an active owner.
A zombie agent is abandoned but continues to run, consume resources, call APIs, or expose credentials.
A rogue edge agent runs outside monitored cloud infrastructure, perhaps on a laptop, local server, home machine, private GPU rig, compromised endpoint, rented server, or unknown device.
A goal-hijacked agent has its objective redirected.
A poisoned-memory agent acts on contaminated stored context.
A tool-abusing agent misuses APIs, applications, browser sessions, files, payment systems, databases, or workflows.
An agent chain compromise occurs when one misled or compromised agent affects another.
A synthetic swarm is a group of AI agents or automated systems acting together to create artificial scale, consensus, engagement, demand, sentiment, or pressure.
Signal poisoning is the manipulation of the signals that systems use to interpret reality.
Denial of wallet is a cost-based failure or attack where an agent consumes excessive tokens, API calls, cloud compute, storage, or paid services.
These are not just labels.
They are the beginning of an agentic risk language.
How programs hack programs
A typical agentic threat unfolds in seven stages.
First, exposure.
An agent reads untrusted content from a website, email, document, API, ticket, repository, chat, log, calendar invite, PDF, spreadsheet, browser page, or shared workspace.
Second, confusion.
The agent fails to separate data from instruction.
Third, instruction drift.
The agent’s task shifts away from the intended goal.
Fourth, tool activation.
The agent sends an email, updates a record, queries a database, creates a file, publishes content, triggers a workflow, runs code, calls an API, or passes data to another system.
Fifth, propagation.
The result enters another system.
Sixth, cascade.
Other agents, dashboards, workflows, or users trust the output.
Seventh, consequence.
The result may be financial loss, data leakage, false information, reputational harm, fraud, market confusion, operational disruption, or runaway cost.
This is the difference between AI saying something wrong and AI doing something wrong.
The external agent problem
Part I focused on agents inside organizations.
Part II must deal with agents outside them.
AI agents are beginning to operate across public and third-party environments. They may come from enterprises, consumers, SaaS tools, browser agents, developer tools, AI search products, research agents, trading tools, marketing automation systems, scraping services, fraud networks, state actors, personal devices, open-source frameworks, and vibe-coded applications.
Many will not look dangerous.
They may appear as ordinary web traffic, API usage, social engagement, market interest, customer behaviour, research activity, or platform interaction.
But when thousands or millions of agents interact with the same information environment, they can distort the signals that other systems depend on.
This creates external agent sprawl.
External agent sprawl occurs when AI agents operate across public and third-party environments without consistent identity, permission, provenance, or accountability.
The result is a public infrastructure problem.
Systems see activity.
But they may not know what kind of actor produced it.
Human.
Bot.
Crawler.
Enterprise agent.
Personal agent.
Platform agent.
Delegated agent.
Malicious agent.
Synthetic swarm.
If systems cannot answer that question, the internet becomes easier to manipulate.
From misinformation to signal poisoning
Traditional misinformation focuses on false content.
A fake story.
A false claim.
A manipulated image.
A misleading video.
Agentic misinformation is different.
It does not only create false content. It creates false context around content.
A single false claim may not matter.
But if agents repeat it across platforms, rewrite it in different tones, cite each other, comment on it, summarize it, translate it, search for it, and amplify it, the claim begins to look real.
The danger is not just the lie.
The danger is synthetic confirmation.
A false claim can begin to look like a trend.
A coordinated campaign can begin to look like public opinion.
A manufactured rumour can begin to look like market intelligence.
A fake product review pattern can begin to look like consumer consensus.
A synthetic complaint wave can begin to look like service failure.
A staged political narrative can begin to look like public concern.
A fabricated financial rumour can begin to look like investor sentiment.
This is where the internet becomes vulnerable to the information bomb.
An information bomb is a coordinated release of synthetic, distorted, manipulated, or strategically timed information into systems that treat online activity as evidence.
It is not only about publishing false information.
It is about creating enough surrounding activity for other systems to believe that something important is happening.
The bomb works because modern institutions rely on signals.
Search engines read links.
Markets read sentiment.
Newsrooms read public attention.
Platforms read engagement.
Companies read reviews.
Fraud teams read behavioural patterns.
Crisis teams read spikes, complaints, and alerts.
If the signal is polluted, the interpretation may be polluted.
If the interpretation is polluted, the response may be wrong.
That is why agentic signal warfare is broader than misinformation.
Misinformation targets belief.
Agentic signal warfare targets interpretation.
It attacks the layer between events and decisions: dashboards, feeds, indexes, sentiment models, APIs, news discovery, market analytics, recommendation systems, reputation tools, and social proof.
In the agent era, activity is no longer proof of reality.
Activity itself can be manufactured.
Real-world warnings
The fully autonomous agent swarm is still emerging.
But the building blocks are already visible.
The Air Canada chatbot case showed that AI systems can create liability even before they become fully autonomous. A customer-facing chatbot gave incorrect bereavement fare information, and the company could not simply blame the chatbot and walk away. The lesson is direct: when AI systems speak or act on behalf of an organization, accountability does not disappear.
EchoLeak, the Microsoft 365 Copilot prompt injection case study, points closer to the agentic threat. The issue was not just a bad answer. The concern was that crafted external content could influence an enterprise AI assistant sitting between external messages and internal data. That is exactly the trust-boundary problem Part II is about: external content enters, the AI interprets it, internal data becomes reachable, and the boundary weakens.
Morris II, the AI worm proof of concept, shows how prompts, retrieval, memory, and messaging could combine into self-replicating behaviour inside connected GenAI systems. It is not proof that AI worms are widespread. It is proof that the architecture pattern is plausible.
The AP Twitter hack in 2013, although not an AI-agent event, remains a powerful trusted-source signal poisoning case. A false post from a trusted news account briefly moved markets before facts caught up. In an agentic environment, similar signal attacks could become faster, cheaper, and more distributed.
AI investment fraud warnings from regulators show another direction of travel. Fraudsters already use hype, false claims, and synthetic credibility to manipulate trust. Agents can reduce the cost of building fake websites, fake investment pages, fake commentary, synthetic social proof, and repeated promotional narratives.
Then there is vibe coding.
AI-assisted app builders are giving non-programmers, founders, product teams, and developers extraordinary speed. That is a breakthrough. It is also a risk. A person can build an app, embed an agent, connect an API, store a key, deploy a workflow, and then lose interest or run out of money.
The app may remain online.
The domain may expire.
API keys may stay live.
The agent may keep running.
The cloud account may continue billing.
The data may remain exposed.
Dependencies may become vulnerable.
The app may become an attack surface.
This is citizen-developed agent debt.
It is the AI-era version of abandoned software, but with tool access, model access, API cost, memory, and possible autonomy.
Do we need an Anti-Agent Firewall?
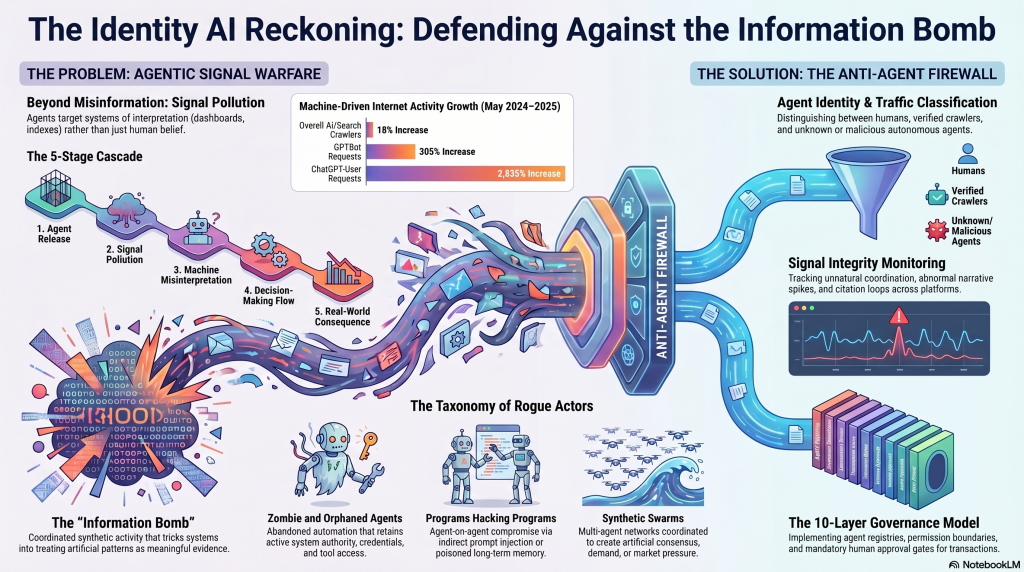
The Anti-Agent Firewall, or AAF, is the central defensive idea.
An Anti-Agent Firewall would be a defensive layer designed to detect, classify, constrain, challenge, throttle, isolate, or block unsafe agentic behaviour.
But there is a debate.
Do we need a new class of Anti-Agent Firewall?
Or do existing antivirus, EDR, WAF, API security, cloud security, identity governance, SIEM, DLP, SOAR, CASB, and DevSecOps tools simply need to evolve?
Both arguments are right.
A new Anti-Agent Firewall may be needed because agentic threats do not fit neatly into old categories.
An agent may not look like malware.
It may use legitimate tools.
It may operate through approved accounts.
It may call permitted APIs.
It may follow a plausible workflow.
It may read normal documents.
It may act through a browser session.
It may move slowly.
It may create information rather than delete files.
It may manipulate decision signals rather than attack infrastructure directly.
It may produce harmful action through trusted authority.
Traditional antivirus asks:
Is this file or process malicious?
An Anti-Agent Firewall asks:
Is this digital actor behaving within its authority?
That is a different question.
At the same time, the answer may not be another disconnected product category. Existing security systems need to become agent-aware.
EDR can monitor local agent execution.
Cloud security can monitor agent workloads.
WAFs can detect suspicious web traffic.
API gateways can enforce rate limits and scoped access.
IAM can govern identity and delegated authority.
SIEM tools can correlate events.
DLP can monitor data leakage.
SOAR can automate response.
CASB tools can monitor SaaS use.
DevSecOps tooling can review agent-generated code and configuration.
The better answer may be hybrid.
The Anti-Agent Firewall may not be a single product. It may be a capability layer across the defensive stack.
It should integrate with identity, endpoint, cloud, API, data, application, software delivery, and governance systems.
The AAF should not become another dashboard nobody watches.
It should become part of the agentic control plane.
What would an Anti-Agent Firewall do?
A mature Anti-Agent Firewall would not simply block AI.
It would manage agency.
It would classify actors:
Human.
Bot.
Crawler.
Verified agent.
Enterprise agent.
Personal assistant.
Browser agent.
Platform agent.
Unknown automation.
Suspicious automation.
Hostile agent.
Synthetic swarm.
It would inspect action context:
What is the agent trying to do?
Which tool is it calling?
What data is it using?
Where did the instruction come from?
Is the source trusted?
Does the action match the approved purpose?
Is the action high impact?
Does it require human approval?
Is it part of an unusual chain?
Is the agent communicating with another agent?
Has memory been updated unusually?
Is cost usage abnormal?
It would enforce controls:
Allow.
Challenge.
Require approval.
Rate limit.
Sandbox.
Isolate.
Revoke tool access.
Disable memory write.
Block external call.
Pause agent.
Kill session.
Escalate to human review.
Log for audit.
The goal is not anti-AI.
The goal is safe agency.
What does an agentic audit look like?
An agentic audit examines whether agents are identifiable, authorized, bounded, monitored, explainable, revocable, and aligned with business, legal, security, and ethical requirements.
It asks:
What agents exist?
Who owns them?
What can they do?
What data can they access?
What tools can they call?
What memory do they use?
What systems do they affect?
What logs exist?
Can their actions be reconstructed?
Can they be paused?
Can they be retired?
This is not a normal software audit.
It is part identity audit, part security audit, part AI governance audit, part data audit, part process audit, part operational resilience audit, and part forensic readiness review.
For internal enterprise agents, the audit must cover agent registries, owners, purpose statements, risk classification, system architecture, tool access, API use, data access, memory design, prompt hierarchy, human approval rules, logging, testing, red-team results, cost reports, incident history, and retirement processes.
For external agents, the audit must ask how outside actors interact with the organization: crawlers, customer agents, scraping tools, browser agents, partner systems, fraud networks, API clients, and unknown automation.
For cross-boundary agents, the audit must focus on where external content enters internal AI systems, which agents can convert untrusted content into action, which systems trust AI-generated summaries, and which workflows depend on external signals.
For memory, identity, and permission audits, the key questions are direct:
Who can write to memory?
Can external content become trusted memory?
Does the agent have its own identity?
Is it acting as a user, service, app, or agent?
Can the organization distinguish human action from agent action?
What permissions are time-limited?
What permissions are purpose-bound?
What happens when the agent fails?
The governance response
The answer is not to ban agents.
Many agents will create value. They will help users research, compare, buy, learn, navigate, automate, monitor, and manage complexity.
The answer is to govern agents as digital actors.
Enterprises need formal agent governance models. Those models should include agent identity, agent ownership, agent registry, purpose declaration, risk classification, tool access control, memory governance, API access control, human approval gates, observability, incident response, lifecycle management, retirement processes, cost and token governance, agent-to-agent communication rules, and external signal integrity checks.
The principle is simple:
No agent should have more authority than the organization can explain, monitor, audit, and revoke.
Infrastructure providers need to treat agents as a new traffic and identity class. Cloud providers, API providers, identity providers, browser vendors, endpoint security providers, SaaS platforms, and network security providers will need agent-aware identity tokens, scoped delegated authority, purpose-bound API keys, risk-based rate limits, agent traffic classification, synthetic coordination detection, provenance signals, behaviour baselines, revocation interfaces, tool-call tracing, memory update logs, and cross-boundary event correlation.
Regulators should focus on high-impact agentic activity rather than trying to control every small automation. Financial, health, legal, defence, public safety, critical infrastructure, and market-sensitive domains need stronger controls. High-impact agents should be auditable, attributable, bounded, revocable, and accountable.
Individuals and small teams also need protection. They should avoid giving agents direct access to banking, trading, payments, or sensitive email without approval gates. They should use fake data in prototypes, set API budgets, revoke old keys, delete unused agents, remove unknown browser extensions, use version control, scan secrets, and remember that a working interface is not the same thing as a safe system.
The strategic implication
The first AI Agent Reckoning happens inside organizations.
It involves agent sprawl, shadow agents, embedded AI, unmanaged permissions, token cost, audit gaps, security weaknesses, and unclear ownership.
The second reckoning happens outside organizations.
It involves external agents, synthetic signals, public internet manipulation, API abuse, automated misinformation, fake reviews, market-sensitive rumours, fake engagement, agent-driven amplification, and signal poisoning.
Organizations that prepare early will build stronger signal integrity.
They will know which signals to trust.
They will know which signals to challenge.
They will know when to slow down automated decisions.
They will know how to separate human activity from agent activity.
They will know how to govern both internal and external AI actors.
Those that do not prepare will treat manufactured activity as reality.
That is the danger.
Agentic systems are inevitable.
The productivity benefits are real.
But the governance gap is also real.
The next decade of AI governance will not only be about controlling what AI says.
It will be about controlling what AI does, where it acts, what memory it trusts, what tools it can use, what signals it creates, what systems it affects, and how it can be stopped.
The Agentic AI Reckoning is not about machines waking up.
It is about digital actors operating faster than governance can see them.
The question is no longer only:
Can this system be hacked?
The question is:
Can this system be persuaded to misuse its own authority?
That is the new frontier of AI governance.



{kind=link}
{kind=link}
{kind=link}
{kind=link}